Yang, Y., Zha, K., Chen, Y. C., Wang, H., & Katabi, D. (2021). Delving into Deep Imbalanced Regression. arXiv preprint arXiv:2102.09554.
In Short
Imbalanced Regression(not classification) with LDS and FDS using kernel function
1. Introduction
불균형데이터에 대해서 학습할 때, 많은 경우에 회귀 문제보다는 분류 문제에 초점이 맞춰져있다. 그러나 현실에서는 연속형 데이터가 불균형인 경우도 충분히 있다. 예를 들어, 연령 분포 데이터의 경우에는 각 나라에 따라서 나이대별 분포가 다르다. 이외에도 혈압이나 맥박수와 같은 환자 활력 징후 데이터나 응급실 체류시간과 같은 데이터들도 그 예시가 될 수 있겠다.
2. Related Work
2-1. Imbalanced Classification
- Data-level
- ROS (Random Oversampling)
- RUS (Random Undersampling)
- SMOTE
- GAN (CGAN, FSC-GAN, MFC-GAN)
- Algorithm-level
- Inverse frequency weight
- Square root weight
- Focal Loss
- Two Stage Training
2-2. Imbalanced Regression
불균형 연속형 데이터 특징
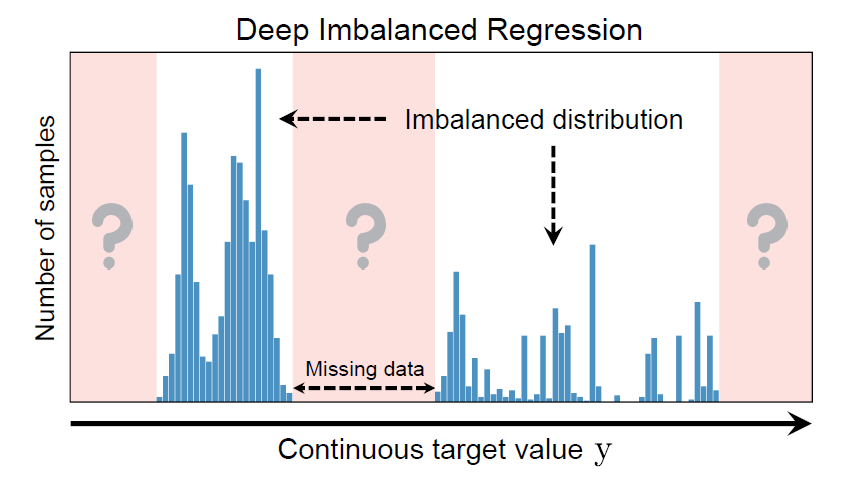
- 클래스 구분이 없다.
- 주변값의 분포에 따라 불균형 수준이 다르다.
- 특정 타겟값에 대한 데이터가 없을 수 있다.
위와 같은 특징 때문에 불균형 연속형 데이터의 경우에는 imbalanced classification와 다르다. 그래서…!
- resampling 또는 reweighting 방법을 적용하기 어렵다.
- 불균형/균형 경계가 뚜렷하지 않다.
- 주변 데이터를 통해 interpolation 또는 extrapolation을 해야 한다.
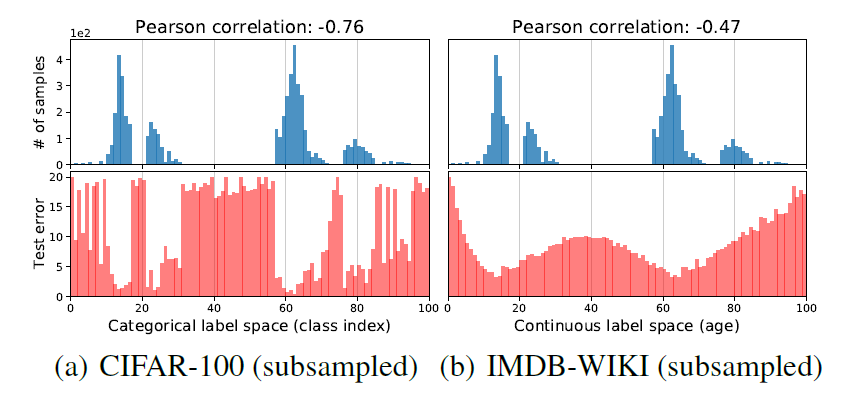
- CIFAR-100: 100개 클래스
- IMDB-WIKI: 0~99세
연속형 데이터의 학습 결과는 범주형 데이터의 학습 결과와 다소 다른 양상을 보인다.
- 범주형 데이터는 불균형의 정도가 오분류율 분포와 밀접한 관계가 있다. (상관계수 -0.76)
- 한편, 연속형 데이터는 불균형 정도가 상대적으로 덜 정확하게 오분류율 분포에 반영된다. (상관계수 -0.47)
3. Methods
Problem Setting
- 인접 데이터 간 유사성 활용
- 커널 함수를 활용하여 불균형 문제 해소
- 커널밀도추정(KDE)
3-1. Label Distribution Smoothing (LDS)
레이블 공간 관점
Figure2에서 보이는 바와 같이, 연속형 데이터와 범주형 데이터가 차이가 나는 이유는 Empirical label distribution과 (unseen data가 포함된) Real label density distribution이 다르기 때문이다. 실제 연속형 데이터는 위에서 언급된 바와 같이 주변 레이블간 연관성을 가진다.
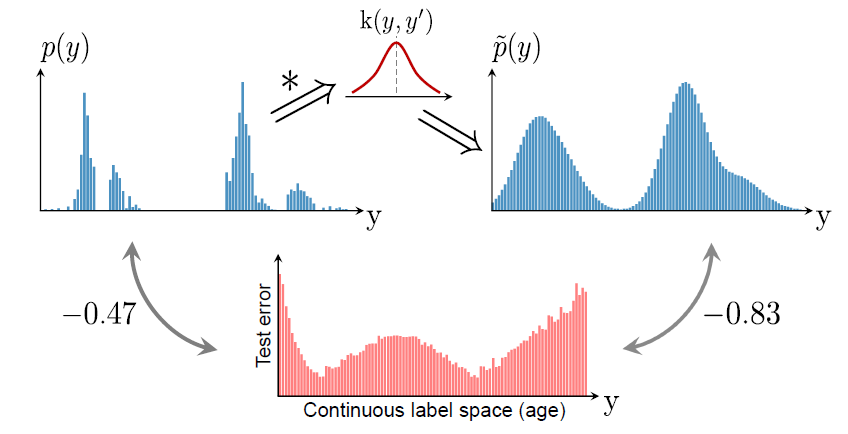
그래서 LDS의 커널 밀도 추정 과정을 통해 주변 데이터의 연속형이 반영된 Effective Label Density를 추출한다. 이렇게 되면, 예측 태스크에 영향을 미치는 실제 불균형 정도를 잘 반영하게 됨을 알 수 있다. 이는 상관계수가 -0.47에서 -0.83로, 그 절댓값이 상승했다는 점에서도 수치적으로 확인 가능하다. 이로 인해 $\tilde{p}(y')$을 아래와 같이 정의한다면, 이의 역수를 손실함수의 가중치로 활용할 수 있게 된다.
$$
\tilde{p}(y') = \int_{Y}k(y, y')p(y)dy
$$
참고로 여기서 커널 함수란, 원점을 중심으로 대칭이며 적분값이 1인 non-negative 함수를 뜻한다. 대표적으로는 Gaussian 커널 또는 Laplacian 커널이 있다.
3-2. Feature Distribution Smoothing (FDS)
특징 공간 관점
타겟 공간에서의 연속성은 잘 학습된 모델의 특징공간에도 반영된다.
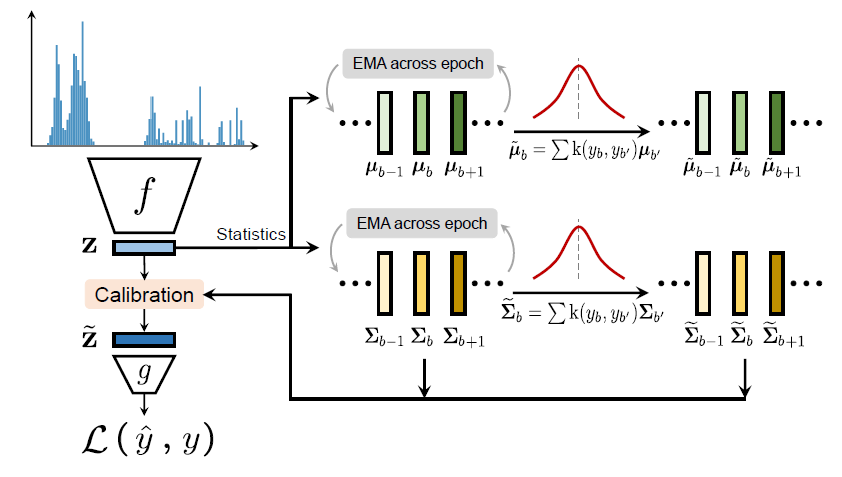
bin = 타겟 공간을 b개로 나누는 동일한 간격 (ex. 연령: 1살)
잘 학습된 encoder를 통해서 특징 공간을 얻을 수 있게 된다. 여기서 인물 image의 특징이 학습된 특징 공간 z에 요약하기 위해서 기초통계량을 구하게 되면, 모든 b에 대해서 평균과 분산을 다음과 같이 구할 수 있다. 이를 기준으로 특정 값 $b_0$를 고정하여두고 다른 $b$의 평균과 분산의 코사인 유사도를 계산한다.
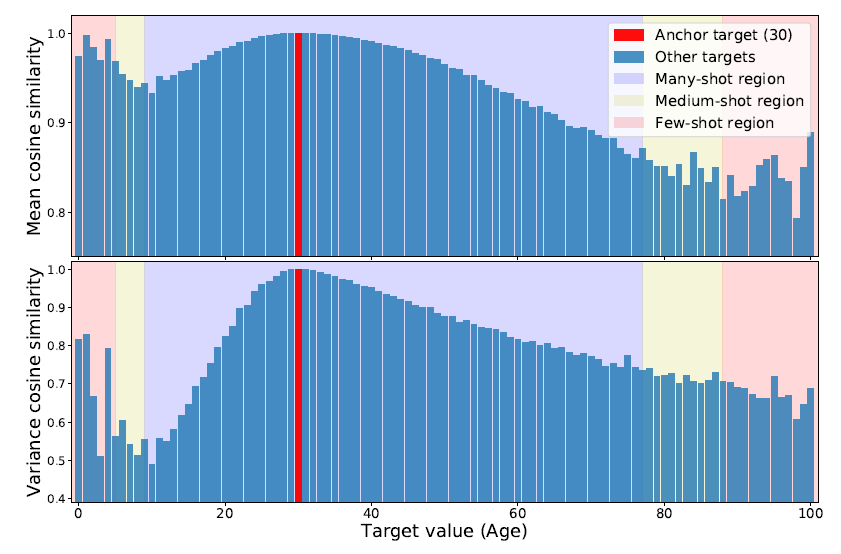
위 그림에서는 일단 30살을 기준으로 코사인 유사도를 계산한 것이다. 상식과 비슷하게, 30살 주변의 값들과는 높은 유사를 나타냈다. 하지만, 특이하게도 0~6살에 해당하는 값들과 유사도가 꽤 높게 나타나는 이상한 현상을 확인할 수 있다. 이는 해당 데이터가 상대적으로 적어서(few-shot region), 즉 데이터 불균형 문제로 인해 발생한 현상이라고 볼 수 있다. 이러한 문제 역시 LDS처럼 커널 함수를 통해 해결한다.
$$\mu_b = \frac{1}{N_b}\sum_{i=1}^{N_b}z_i \rightarrow \tilde{\mu_b} = \sum_{b' \in B}k(y_b,y_{b'})\mu_{b'} \\ \Sigma_b = \frac{1}{N_b-1}\sum_{i=1}^{N_b}(z_i-\mu_b)(z_i-\mu_b)^T \rightarrow \tilde{\Sigma_b} = \sum_{b' \in B}k(y_b,y_{b'})\Sigma_{b'}$$
한 에폭에서 학습된 z의 통계량에 커널함수를 적용해서 calibration시키고, regression layer를 통과시켜서 손실함수를 계산한다.
여기서 LDS와 달리 추가된 부분이 있는데, 이는 바로 업데이트 방식이다. 학습과정에서 안정적이고 정확한 추정치를 얻기 위해서, 매 epoch마다 EMA를 진행한다. 구체적으로 말하자면, 현재 에폭 내에 있는 샘플에 대해서 진행이 되면, 통계량을 업데이트 하기 위해서 모멘텀 업데이트 방식(EMA, exponential moving average)을 활용한다.
그리고나서 마지막으로, 현재 통계량에 커널함수를 적용함으로써 다음 epoch으로 전달해준다.
Calibration
$$\tilde{z} = \tilde{\Sigma}_{b}^{\frac{1}{2}}\Sigma_{b}^{-\frac{1}{2}}(z-\mu_b)+\tilde{\mu_b}$$
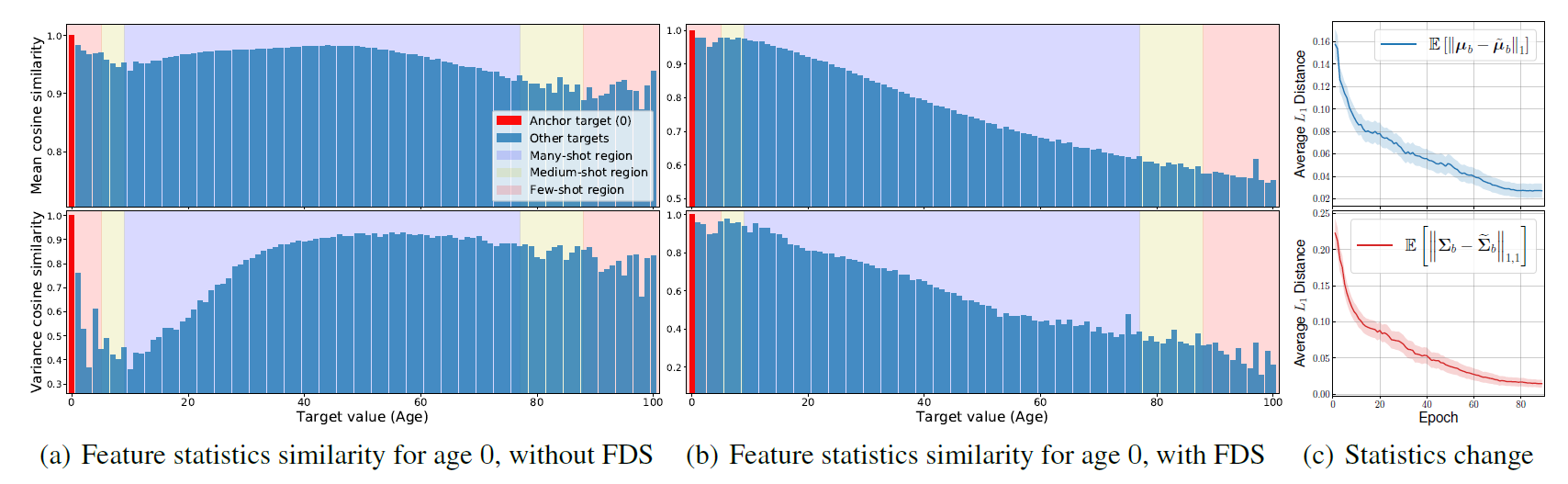
FDS의 결과는 위와 같다. 왼쪽은 FDS를 적용하지 않은 것이고, 오른쪽은 FDS를 적용한 것이다. FDS를 적용한 오른쪽 그래프가 기본적인 상식을 반영하는 것처럼 보인다.
이외에 FDS의 장점을 정리해보자면, 일종의 calibration layer로서 어떤 모델에도 직접적으로 적용될 수 있다는 점이다.
4. Performace Comparison
4-1. Dataset
5개의 Dataset이 사용되었다. 직접 만든 것으로 보인다.
- IMDB-WIKI-DIR (age)
- AgeDB-DIR (age)
- STS-B-DIR (text similarity score)
- NYUD2-DIR (depth)
- SHHS-DIR (health condition score)

각 데이터들은 모두 불균형함을 확인할 수 있다.
4-2. Baseline
imbalanced classfication에서 활용되는 방법들을 차용함.
- Synthetic samples: (1) SmoteR (2) SMOGN
- Error-aware loss: (3) Focal-R
- Two-stage training: (4) regressor re-training(RRT)
- Cost-sensitive re-weighting: (5) naive inverse(INV) (6) square-root inverse(SQINV)
이를 (1) LDS (2) FDS (3) LDS+FDS가 추가된 버전과 함께 비교함. 그리고 이 모든 것들 중에서 가장 성능이 좋은 것을 VANILLA와 마지막으로 비교한다.
4-3. Main Results
비교 metrics은 MAE(Mean Average Eror)와 GM(Geometric Mean Error)가 있다.
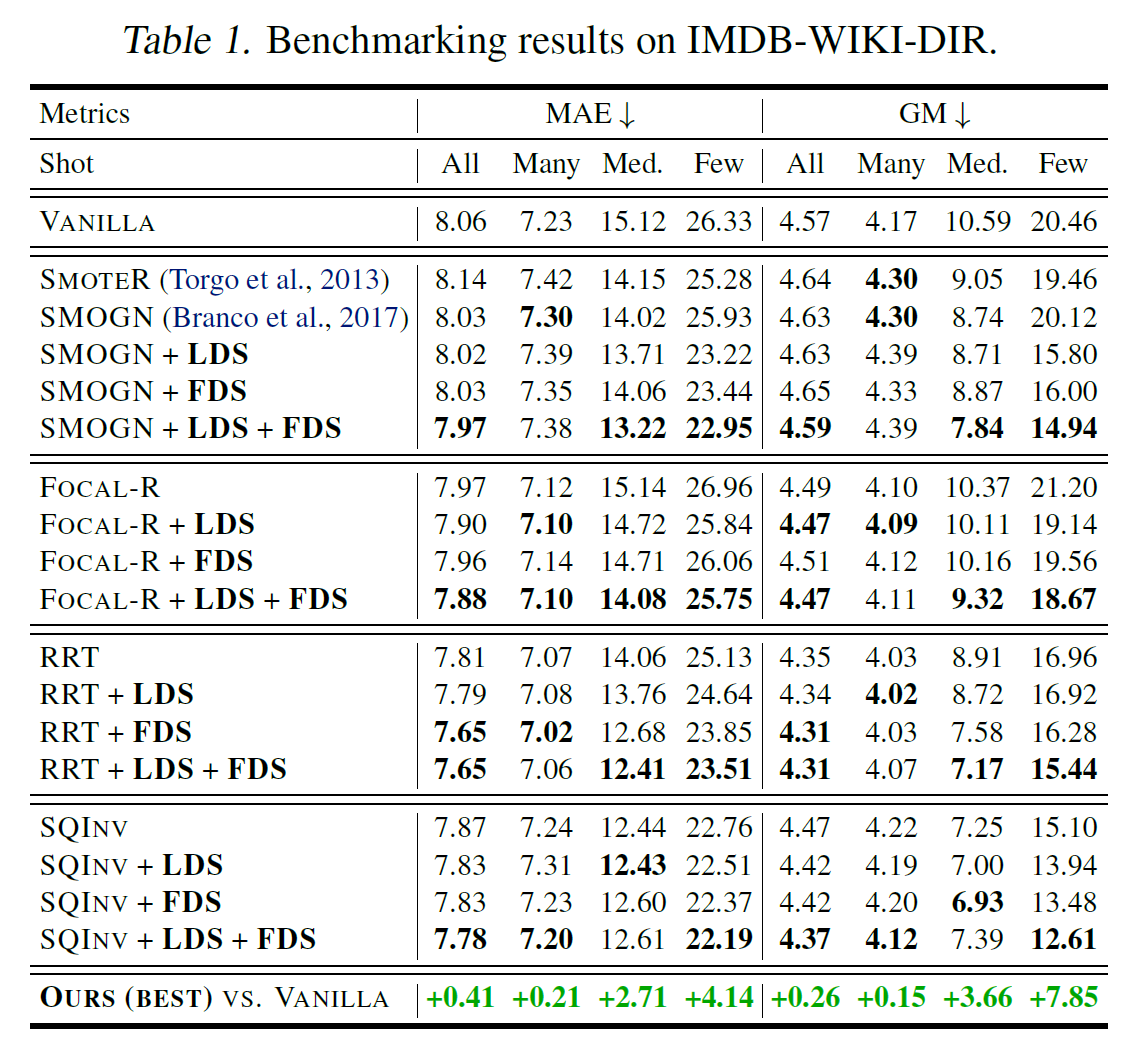
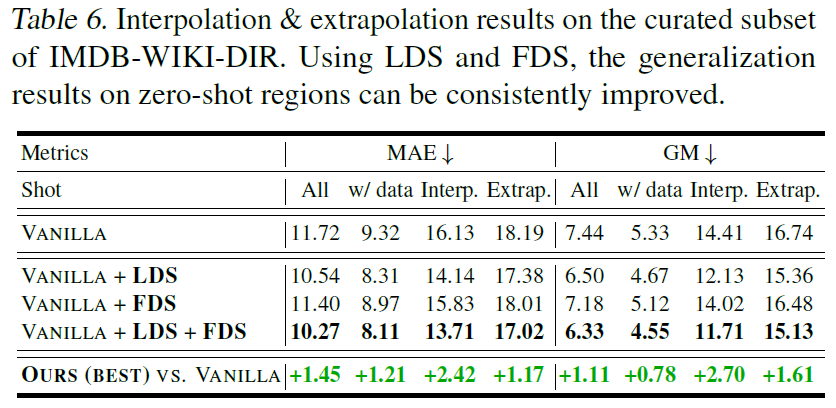
IMDB-WIKI-DIR에서는 위와 같이 Medium-Shot과 Few-Shot에서 특히 유의미한 성능 상승이 있었다는 점이 특히 주목해볼 만하다. 이외의 데이터에서 성능은 아래와 같다.
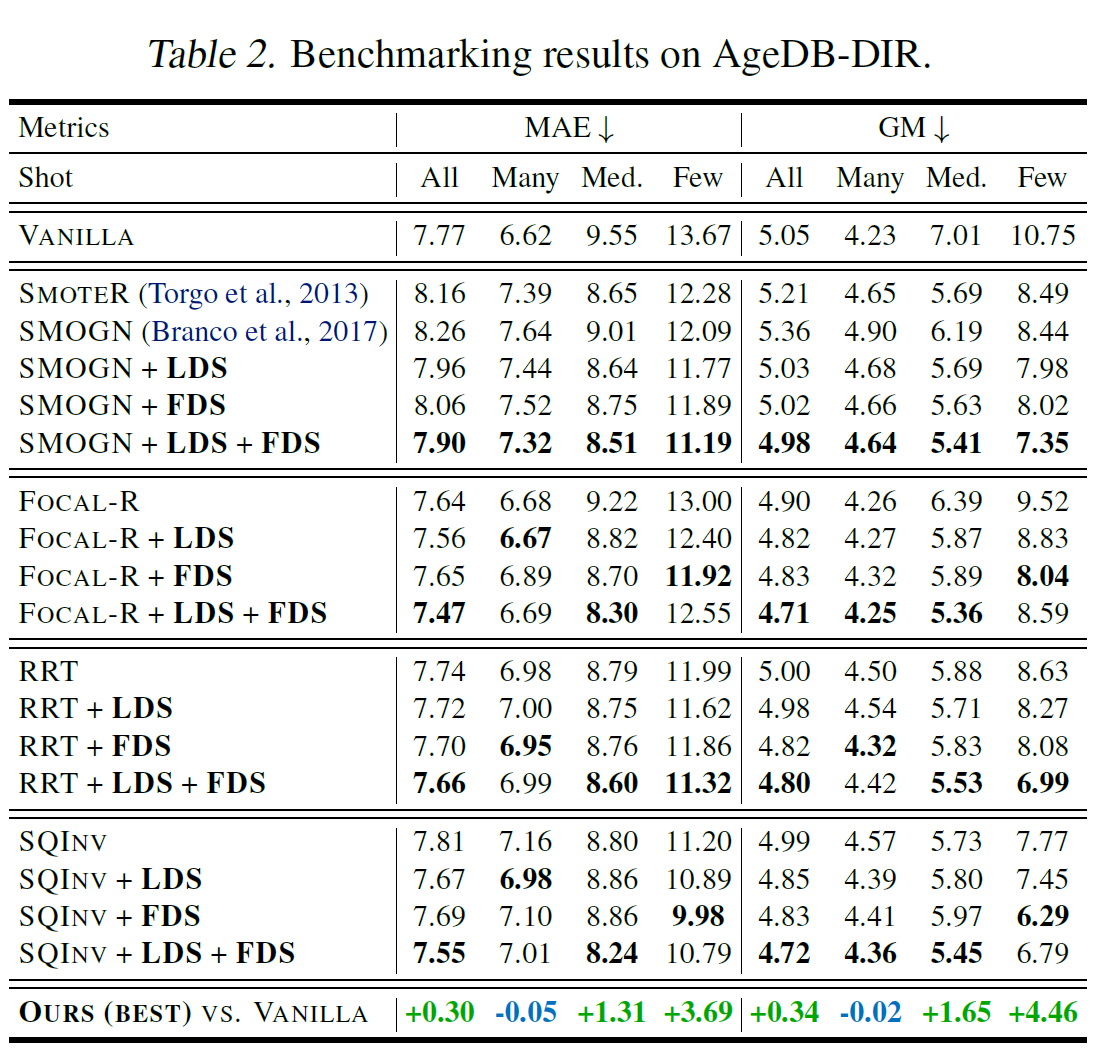
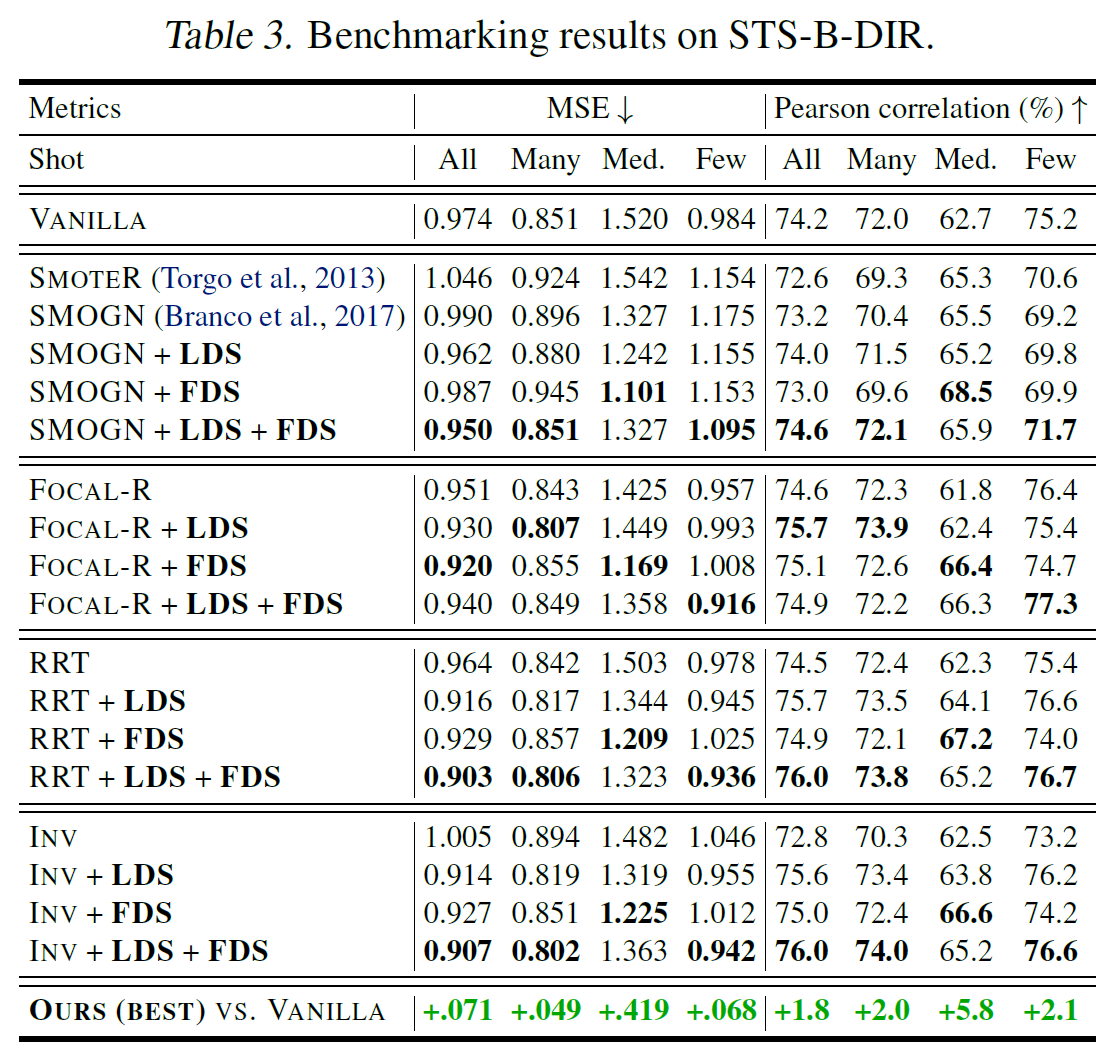
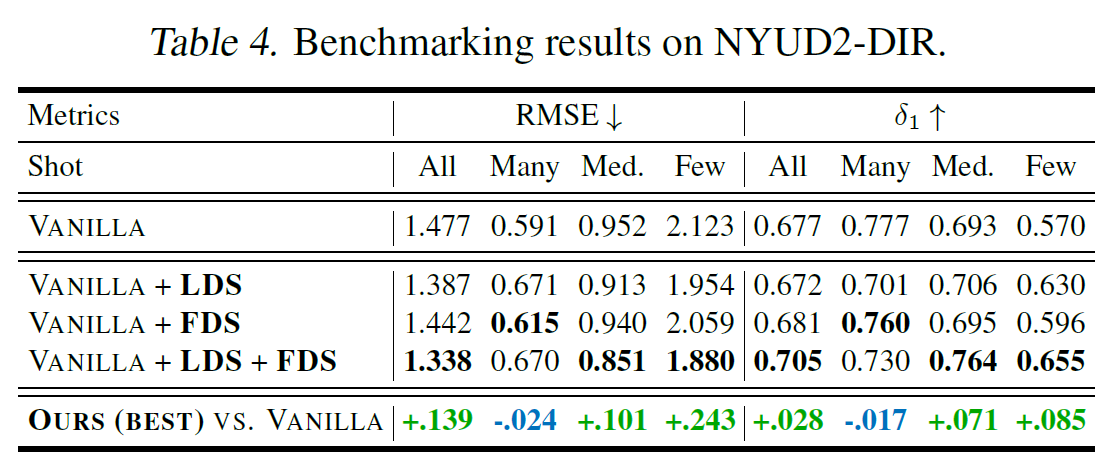
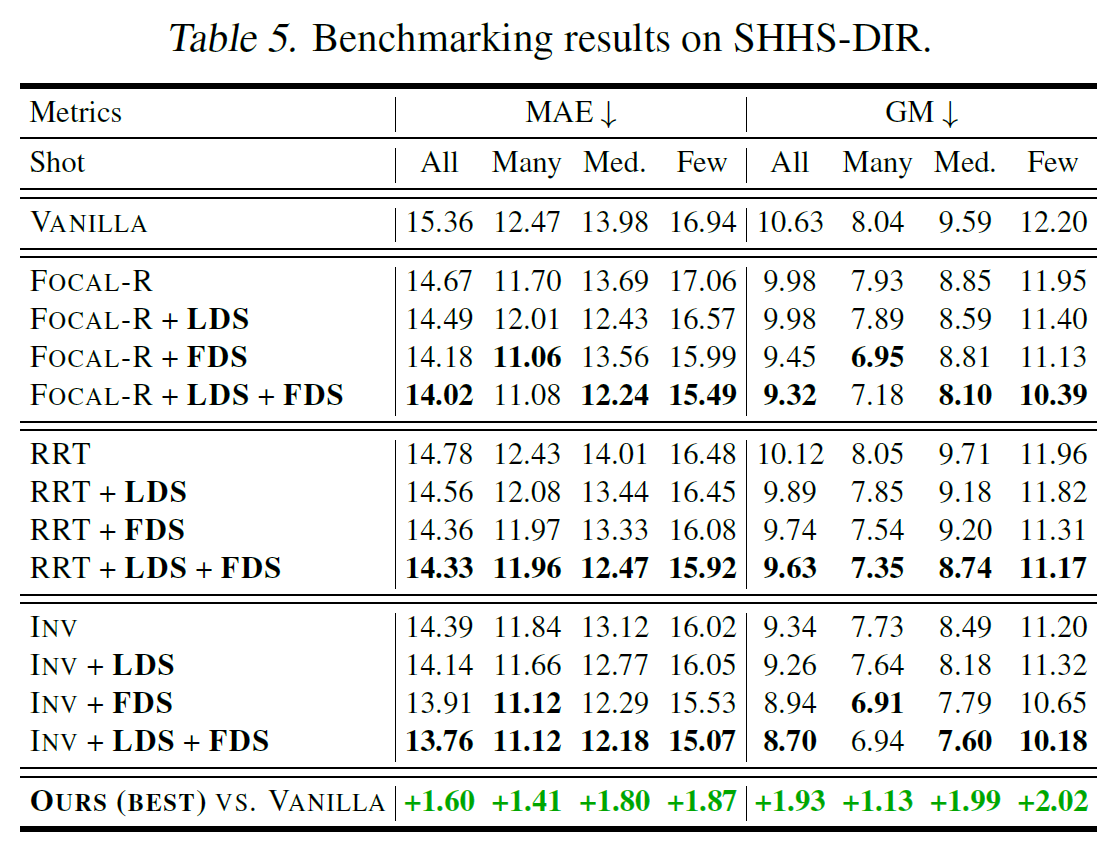
4-4. Further Analysis
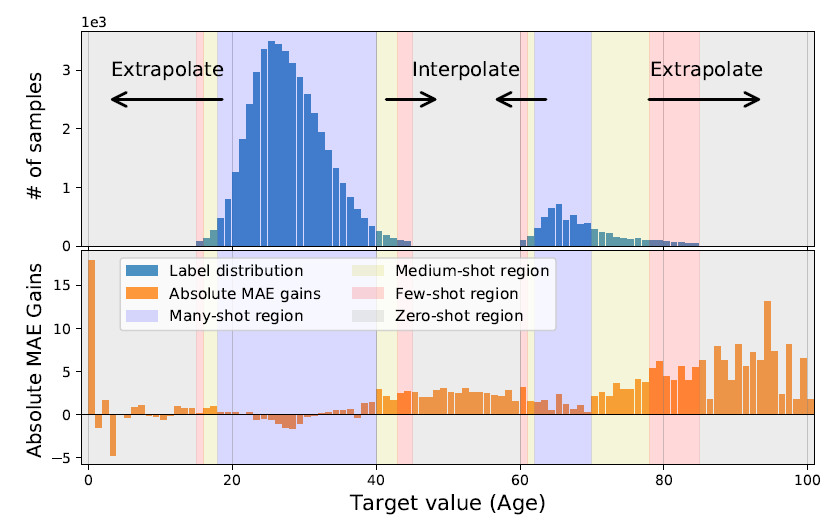
Extraopolation & Interpolation
Training Dataset에는 없고, Test Dataset에는 있는 부분에 대해서의 성능을 이야기하는 것 같다.
5. Conclusion
New task: Deep Imbalanced Regression(DIR)
New techniques: LDS & FDS
New benchmarks: IMDB-WIKI-DIR / AgeDB-DIR / STS-B-DIR / NYUD2-DIR / SHHS-DIR
—
Critical Point (MY OWN OPINION)
- bin을 몇 개의 b로 나눌지에 따라서 성능이 달라질 수 있겠다. 만약 엄청 세분화하게 된다면 성능이 저하될 것으로 예상되는데, 이렇게 본다면 완벽한 연속형 데이터라고는 보기 힘들지 않을까?
—
Reference
[1] Youtube 연구자 발표 영상
[2] Youtube