Audibert, J., Michiardi, P., Guyard, F., Marti, S., & Zuluaga, M. A. (2020, August). Usad: Unsupervised anomaly detection on multivariate time series. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (pp. 3395-3404).
In Short
1. Introduction
- AE-based AD 문제점: 이상치가 정상데이터와 유사하면 Reconstruction Loss가 작아서 탐지 실패
- GAN-based AD 문제점: 불안정한 학습 (mode collapse or non-convergence)
AutoEncoder에 adversarial training을 접목하여 위의 한계점들을 해결하는 모델
2. Related Work
2-1. LSTM-AE
- unsupervised
- Training: 정상데이터의 reconstruction error를 기바으로 LSTM-AE를 학습하여 정상데이터의 분포를 학습함
- Anomaly Detection: 새로운 데이터의 reconstruction error가 threshold를 초과하면 이상치로 탐지함.
$$
\text{Anomaly Score = } \bigg|\bigg|X - D(E(X))\bigg|\bigg|_2
$$
2-2. MAD-GAN
- unsupervised
- Training: 정상데이터만으로 LSTM 구조의 Generator와 Distriminator를 학습하여 정상데이터의 분포를 학습
- Anomaly Score = Reconsctruction Loss + Discrimination Loss
$$
\text{Anomaly Score = } \lambda \Big| X - G(Z) \Big| + (1-\lambda)*D(X)
$$
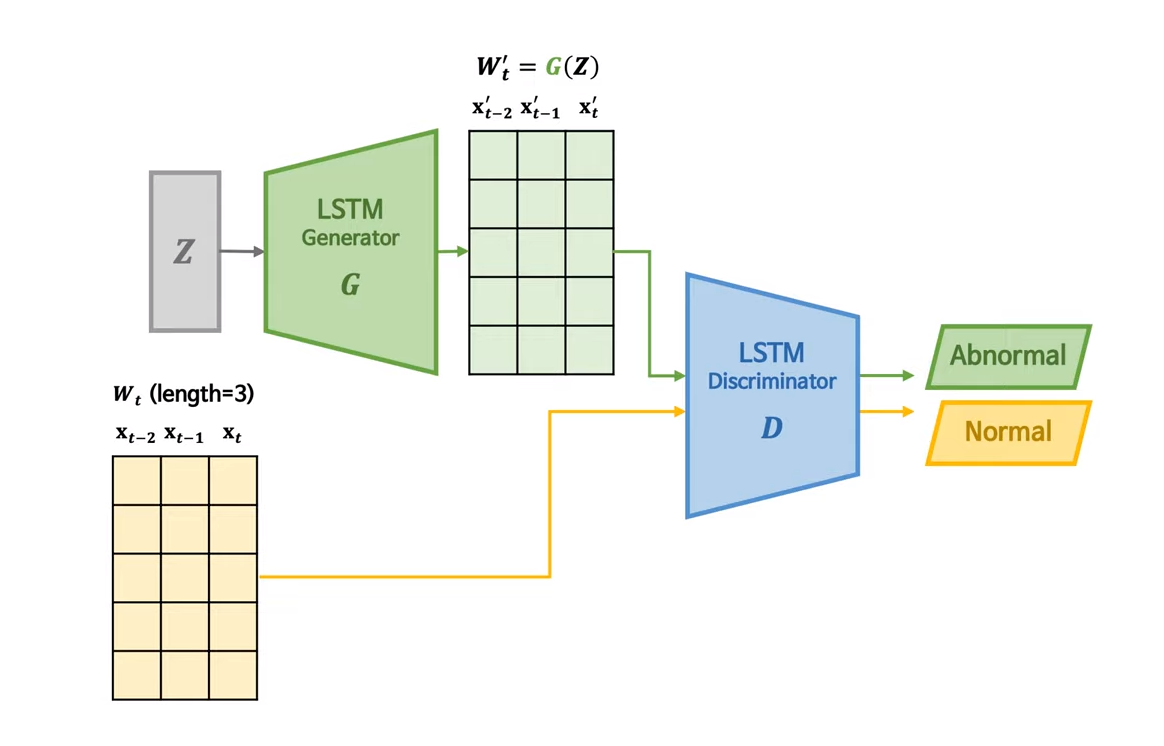
3. Methods
3-1. Autoencoder Training
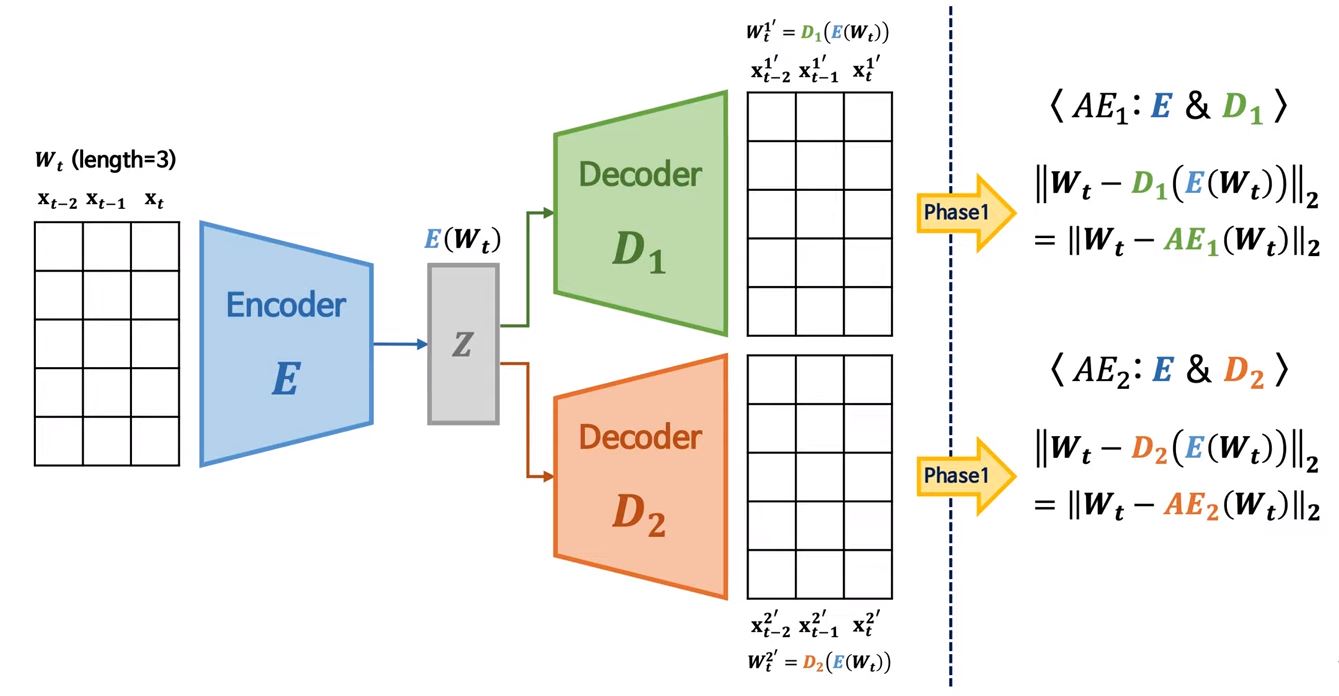
3-2. Adversarial Training
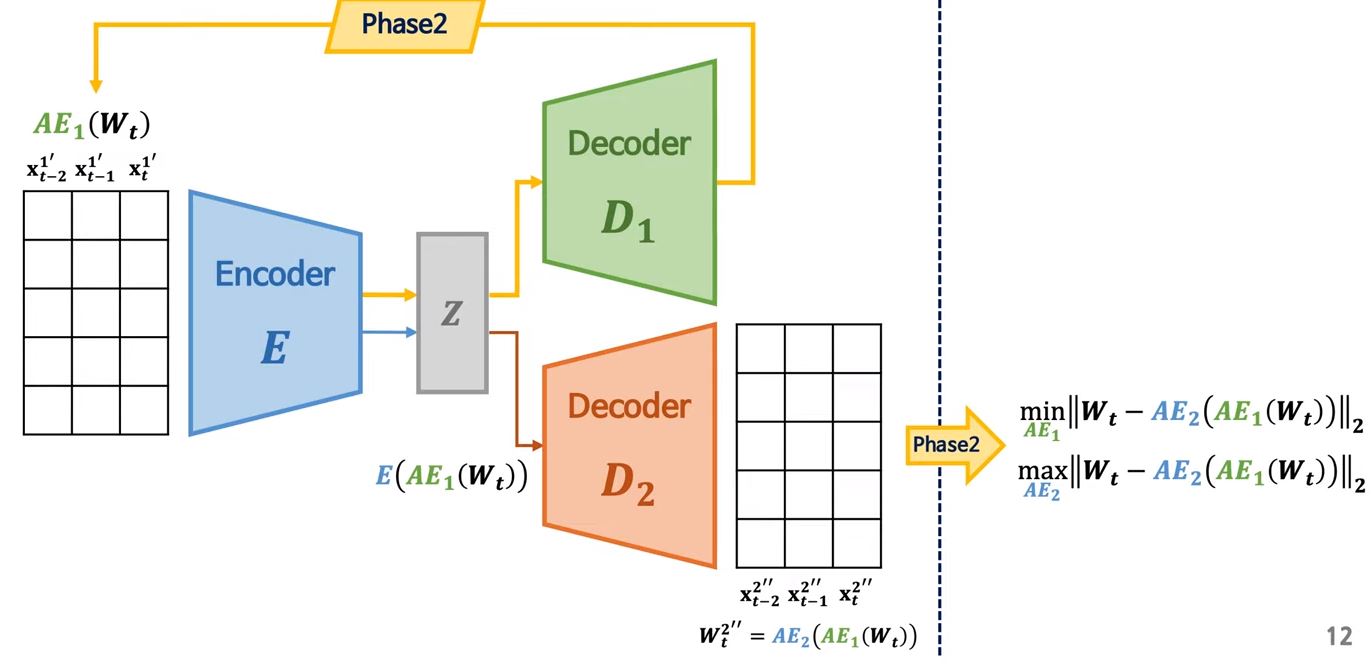
편의상 AutoEncoder1을 AE1, AutoEncoder2을 AE2라고 하겠다.
AE1: (1) input 복원 & (2) AE2 속이기
AE2: (1) input 복원 & (2) AE1이 복원한 데이터와 input 구별
$$
\begin{align} &\min_{AE_1} \frac{1}{n}||X - AE_1(X)||_2 + (1-\frac{1}{n})||X - AE_2(AE_1(X))||_2 \\ &\min_{AE_2} \frac{1}{n}||X - AE_2(X)||_2 - (1-\frac{1}{n})||X - AE_2(AE_1(X))||_2 \end{align}
$$
여기서 n은 epoch이다. 즉, 초반에는 reconstruction loss 학습에 중점을 두고, 점차 adversarial training에 가중치를 부여하는 방식이다.
3-3. Anomaly Score
$$
\text{Anomaly Score = } \alpha \bigg|\bigg| X - AE_1(X) \bigg|\bigg|_2 + \beta \bigg|\bigg| X - AE_2(AE_1(X))\bigg|\bigg|_2
$$
\(\alpha + \beta = 1\)\(\alpha > \beta\): True & False Positive 감소 = Low Detection Sensitivity Scenario\(\alpha < \beta\): True & False Positive 증가 = High Detection Sensitivity Scenario
4. Result
\(\alpha, \beta\)에 민감하다.- 하지만 전반적으로 hyperparameter의 변화로부터 강건하다. (ex. Window size)
5. Conclusion
AutoEncoder에 adversarial training을 접목하여 위의 한계점들을 해결하는 모델
—
Critical Point (MY OWN OPINION)
—
Reference
[1] Youtube 영상