Torgo, L., Ribeiro, R.P., Pfahringer, B., Branco, P. (2013). SMOTE for Regression. In: Correia, L., Reis, L.P., Cascalho, J. (eds) Progress in Artificial Intelligence. EPIA 2013. Lecture Notes in Computer Science(), vol 8154. Springer, Berlin, Heidelberg.
In Short
SMOTE를 회귀분석에 맞게 바꾼 알고리즘이다.
참고로, 위 저자들은 해당 논문이 나오기 6년 전인 2007년에 Utility-based Regression이라는 논문을 썼었고, 여기서 그들이 제안한 개념인 relevance를 활용하여 SMOTER를 제안하고 있다.
1. Introduction
Regression 상황에서도 불균형데이터에 해결책이 필요하다.
2. Problem Formulation
2-1. Utility-based Regression
$$\begin{aligned} U^{P}_{\phi}(\hat{y},y) &= B_{\phi}(\hat{y},y) - C_{\phi}(\hat{y},y) \\ &= \phi(y) \cdot (1-\Gamma_B(\hat{y},y)) - \phi^P(\hat{y},y) \cdot \Gamma_C(\hat{y},y) \end{aligned}$$
\(B_{\phi}(\hat{y},y), C_{\phi}(\hat{y},y), \Gamma_B(\hat{y},y), \Gamma_C(\hat{y},y)\)는 각각 benefit과 cost와 관련된 함수들이다.
2-2. Precision and Recall for Regression
$$\text{recall} = \frac{\sum_{i:\hat{z_i}=1, z_i=1}(1+u_i)}{\sum_{i:z_i=1}(1+\phi(y_i))}$$
$$\text{precision} = \frac{\sum_{i:\hat{z_i}=1, z_i=1}(1+u_i)}{\sum_{i:\hat{z_i}=1,z_i=1} \Big(1+\phi(y_i)\Big) + \sum_{i:\hat{z_i}=1,z_i=0}\Big(2-p\big(\phi(y_i)\big)\Big)} \\ \text{where p is a weight differentiating the types of errors}$$
$$\text{F1-score} = \frac{(\beta^2+1) \cdot precision \cdot recall}{\beta^2 \cdot precision + recall}$$
3. Sampling Approaches
3-1. Under-sampling common values
단순하게 rare target value를 oversampling하는 것이 아니라, normal case도 추가적으로 undersampling하는 hybrid 방식이다. 왜냐하면 rare value를 oversampling할 때 그 비율을 normal과 1:1로 하는 것이 아니기 때문에 여전히 불균형도가 남아있을 수 있기 때문이다.
3-2. SMOTE for regression
Point 1. how to define which are the relevant observations and the normal cases
Point 2. how to create new synthetic examples (i.e. oversampling)
Point 3. how to decide the target variable value of these new synthetic examples


- Algorithm2에서 오류가 있다.
new[a] <- case[a] + RANDOM(0,1) X diff가 아니라 new[a] <- x[a] + RANDOM(0,1) X diff이다.
4. Experimental Evaluation
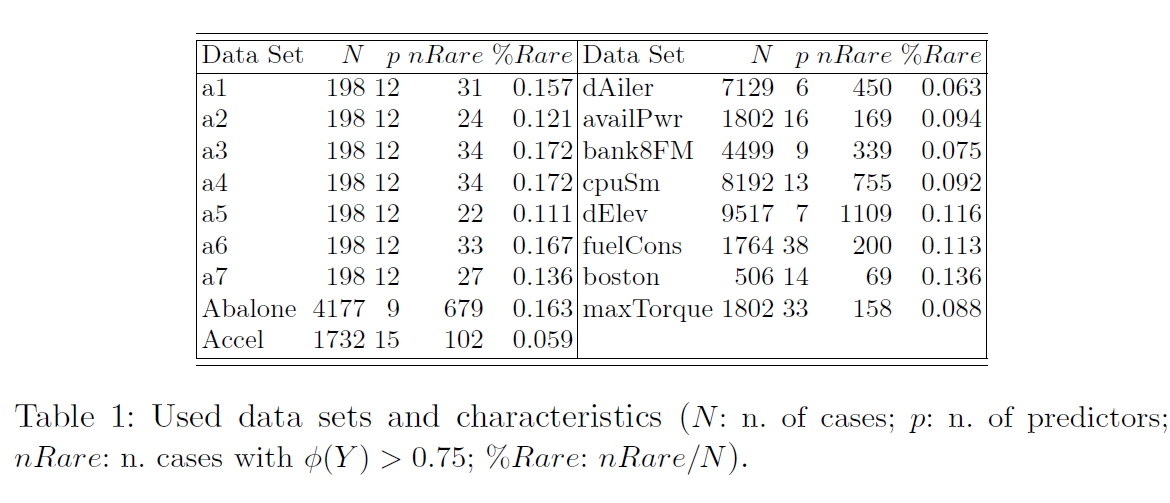

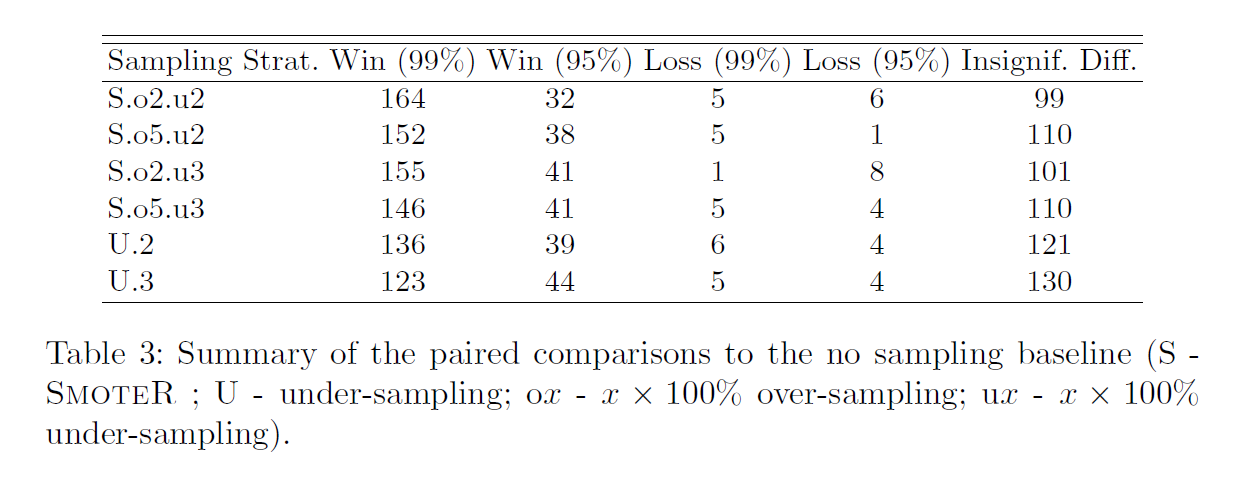
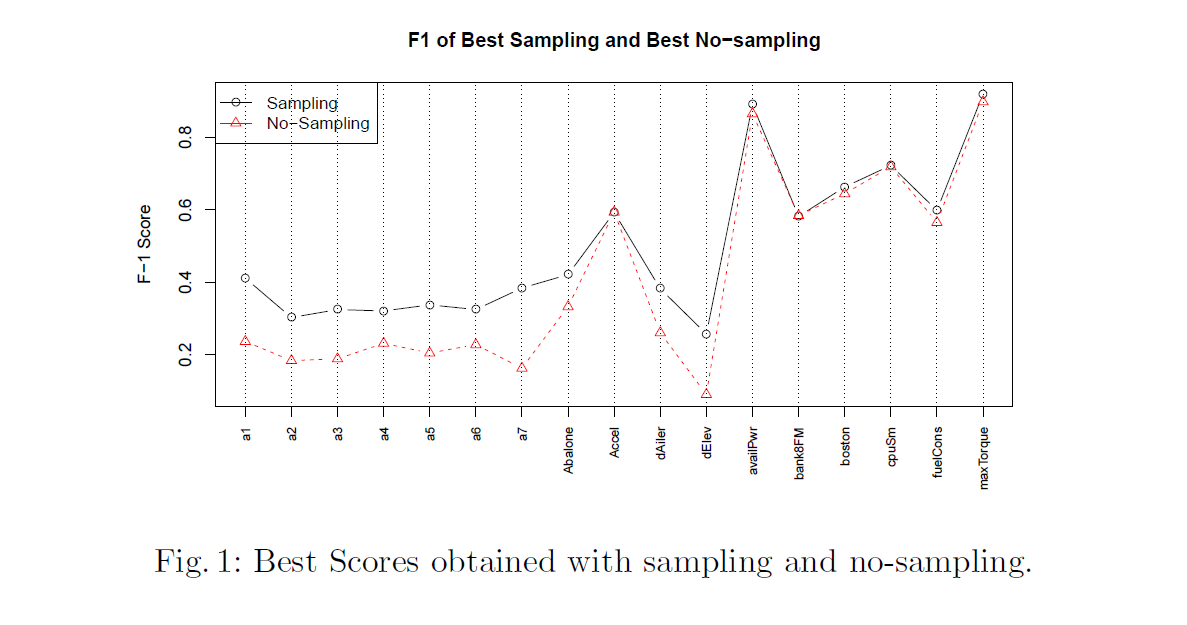
200% oversampling and 200% undersampling이 가장 효율적인 조합이었다.
5. Conclusions
rare extreme value를 예측하는데에 기여하였다.
—
Critical Point (MY OWN OPINION)
- Regression에서 SMOTE를 제안했다는 데에 큰 의의가 있는 것 같다.
- Oversampling하는 과정에서 distance를 계산하기 때문에 Scaling이 굉장히 중요할 것 같다. 그리고, categorical variable과 numerical variable를 동시에 고려하여 거리 계산을 하는 것이기 때문에 중요할 것 같다. SMOTE-NC와 같은 방법으로 계산하는 것 같다.
—
ETC
- R에서는
uba라는 패키지로 relevance function이 구현되어 있다. - 또한, SMOTER의 R 코드도 공개되어있다. (http://www.dcc.fc.up.
pt/~ltorgo/EPIA2013)