KT AI EDU 맞춤형 학습법 가이드 제안
- KT 2022년 하계 석/박사 연구인턴 최종과제
- 소속: KT AI EDU Tech Project S-TF
- 분석기간: 2022 July ~ 2022 August
- POINT: 학습성과 예측모델 및 수강생 군집화 모델 기반
- 기밀사항이다보니 실제 PPT 발표자료는 업로드되지 않을 예정이다. (2022.08.26)
—
What I Have Learned
- 데이터분석을 사후적으로 하는 것이 아니라, 사전적으로 활용할 수 있음을 체감하였다.
원래는 7월 중순부터 데이터가 쌓여서 이를 분석할 계획이었지만, 일정이 밀려서 8월 말부터 서비스가 런칭하여서 실제 데이터보다는 오픈데이터를 토대로 서비스 개선 제안을 하는 방향으로 과제를 잡았다. - 예측 알고리즘과 군집화 알고리즘을 엮어서 최종적으로 사업적으로 의미있는 제안을 했다.
실제로 최종평가 당시 특허를 내거나 논문을 낼 계획이 있는지 질문을 받았다. - 데이터를 단순하게 이해하는 것이 아니라, 사업성까지 이어가려는 실질적 노력을 경험하였다.
—
Index
- AI 튜터링 플랫폼 개요
- 과제목표 및 범위
- 과제수행 방법
- 학습성과 예측모델
- 수강생 군집화 모델
- 적용 예시
- 기대효과 및 향후 계획
- Appendix
1. AI 튜터링 플랫폼 개요
학생과 강사를 매칭해주고, 축적된 데이터를 통해서 최적의 학습환경을 제공한다. AI 학습진단과 AI 매칭/추천 서비스가 있다. KT에서는 초등 라이브교육 플랫폼 ‘크루디’가 대표적으로 있다.
2. 과제목표 및 범위
수강생 맞춤형 학습법 제공 / 학습초기부터 적용 가능
- 학습성과 예측 모델 개발
- 수료여부: 100% 예측
- 수료점수: 93% 오차 5점 이내
- 수강생 군집화 모델 개발
- 군집별 주요 특징 파악
- 총 3개 그룹
위 두 모델을 토대로 군집별 맞춤형 학습법 전략을 만들고 이를 토대로 맞춤형 학습법 제공하는 것이 최종 목표이다. 참고로, 최종적으로는 5개 그룹으로 나누었다. 해당 아이디어는 학습초기부터 적용 가능하며, 후반까지도 활용 가능한 아이디어다.
3. 과제수행 방법
1. 데이터 수집
온라인 포털/통계 사이트 등을 확인하였다. 10개 남짓의 데이터를 수집 후 비교해본 결과, 한국청소년활동진흥원의 ‘온라인교육 수강패턴 데이터’가 추후 수집될 유사하였다.
2. 데이터 정의
결측치를 제거한 10,514개 데이터가 있었다. 특징이 상이한 50개 이상의 과목을 수강한 학생들에 대한 데이터였다. 해당 데이터를 분석하는 데에 어려웠던 점 중 하나는 수업마다 수료기준과 같은 세부 디테일들이 달랐는데, 수업의 특성을 사전에 미리 알 수 없었다는 점이다.
- 기존변수: 교육비용, 지도율, 과제여부, 과제점수, 과제제출여부
- 파생변수: 학습기간, 일평균학습중접속횟수, 유료강좌여부, 최종평가환산비율, 최종평가필수
- 타겟변수: 수료점수, 수료여부
3. 모델 연구
STEP1. 15개 이상 머신러닝 알고리즘 기법 적용 (pycaret 활용)
STEP2. Top1(STEP1 중 BEST), CatBoost, LightGBM, XGBoost 선택
STEP3. 4개 모델 하이퍼파라미터 최적화 (성능 고도화)
4. 학습성과 예측모델
수료여부는 정확도를 높이고, 수료점수를 오차를 줄이며 성능 고도화 후 최종모델 선정
1. 예측 #1. 수료 여부
1-1. 평가지표: F1 Score (Recall과 Precision의 조화 평균)
1-2. 성능: F1-Score=1.00 (100%의 학생들에 대해서 정확하게 수료 여부 예측)
1-3. 최종모델: XGBoost
2. 예측 #2. 수료 점수
2-1. 평가지표: MSE (Mean Squared Error)
2-2. 성능: MSE=11.01 (약 93%의 학생들에 대해서 오차를 5점 이내로 예측)
2-3. 최종모델: CatBoost
2-4. 특이사항: SMOTE-Tomek을 통해 데이터 합성 (18,568개, 기준:수료여부)
*SMOTE-Tomek: Tomek’s Link 방법으로 소수 데이터와 비슷한 다수 데이터는 제거하고, SMOTE 방법으로 소수 데이터와 다수 데이터의 개수를 같게 하는 Hybrid 방법
5. 수강생 군집화 모델
5-1. 군집화 모델 과정 및 결과
유사한 학습 패턴을 가진 학생들의 군집화를 통해 공통특징 파악 후, 미수료학생의 수료전환 가이드 추천
5-1-1. 데이터 변환 및 군집화 과정
- 학습성과예측모델 주요변수 확인
1 데이터 전처리- 연속형 변수: Standard Scaling
- 평균값 빼기
- 표준편차로 나누기
- 범주형 변수
- One-Hot Encoding
- 확률의 제곱근으로 나누기
- 평균값 빼기
- 연속형 변수: Standard Scaling
- PCA (Principal Component Analysis)
- 주성분 개수 선택 (2개)
- Scree Plot
- Kaiser’s Rule
- Explained Variance
- 주성분 개수 선택 (2개)
- 군집화 모델 비교
- Kmeans/ KMedoids/ DBSCAN/ CURE
- Distortion Score
- Silhouette Score
- Kmeans/ KMedoids/ DBSCAN/ CURE
- 최종 군집화 모델 선정
- Kmeans Clustering with K=3
5-1-2. 군집화 결과

군집 1: 111명 (보라색)
군집 2: 2641명 (하늘색)
군집 3: 7762명 (분홍색)
그룹 내에서도 수료 학생들과 미수료 학생들 간의 차이가 있었다. 특히 그룹2와 그룹3은 수료여부를 기준으로 다시 한 번 학생들을 분류할 필요가 있다. 즉,수강생은 총 다섯 군집으로 나누어서 분류 필요
5-2. 맞춤형 학습 가이드
군집별 특징 추출 및 특징에 따른 맞춤형 학습법 제시
미수료 3군집, 수료 2군집으로 총 5군집으로 학생들을 나누었다.
- 진도율이 심각하게 낮은 학생 (미수료1)
- 특징(1) 긴 학습기간 (23일)
- 특징(2) 진도율 10%
- 특징(3) 낮은 참여도
- 맞춤형 학습법 가이드(1) 학습독려 카톡 알람
- 맞춤형 학습법 가이드(2) 추가접속 출석이벤트
- 맞춤형 학습법 가이드(3) AI 학습모니터링 강화
- 참여도는 높지만 과제를 미제출한 학생 (미수료2)
- 특징(1) 짧은 학습기간 (6일)
- 특징(2) 과제 미제출
- 특징(3) 높은 참여도
- 맞춤형 학습법 가이드(1) 과제제출 알람빈도 UP
- 맞춤형 학습법 가이드(2) 과제난이도 조절
- 맞춤형 학습법 가이드(3) 퀴즈시간 알람빈도 UP
- 맞춤형 학습법 가이드(4) 복습 권장 및 유도
- 진도율은 높지만 끝까지 못 들은 학생 (미수료3)
- 특징(1) 긴 학습기간 (27일)
- 특징(2) 진도율 80%
- 특징(3) 낮은 참여도
- 맞춤형 학습법 가이드(1) 시청 완료 이벤트
- 참여도가 높은 열정적인 학생 (수료1)
- 특징(1) 짧은 학습기간 (6일)
- 특징(2) 과제제출
- 특징(3) 높은 참여도
- 맞춤형 학습법 가이드(1) 심화문제 추천
- 맞춤형 학습법 가이드(2) 예습 가이드
- 맞춤형 학습법 가이드(3) 심화학습 제안 (과제 많은 참여형 강좌, 동일군집 인기 강좌)
- 참여도는 낮지만 성실한 학생
- 특징(1) 긴 학습기간 (27일)
- 특징(2) 진도율 100%
- 특징(3) 낮은 참여도
- 맞춤형 학습법 가이드(1) 칭찬 메세지 알림
- 맞춤형 학습법 가이드(2) 심화학습 제안 (과제 없는 시청형 강좌, 동일군집 인기 강좌)
6. 적용 예시
수강생의 학습기간동안 이벤트별 군집 배정 및 군집별 맞춤형 학습법 추천
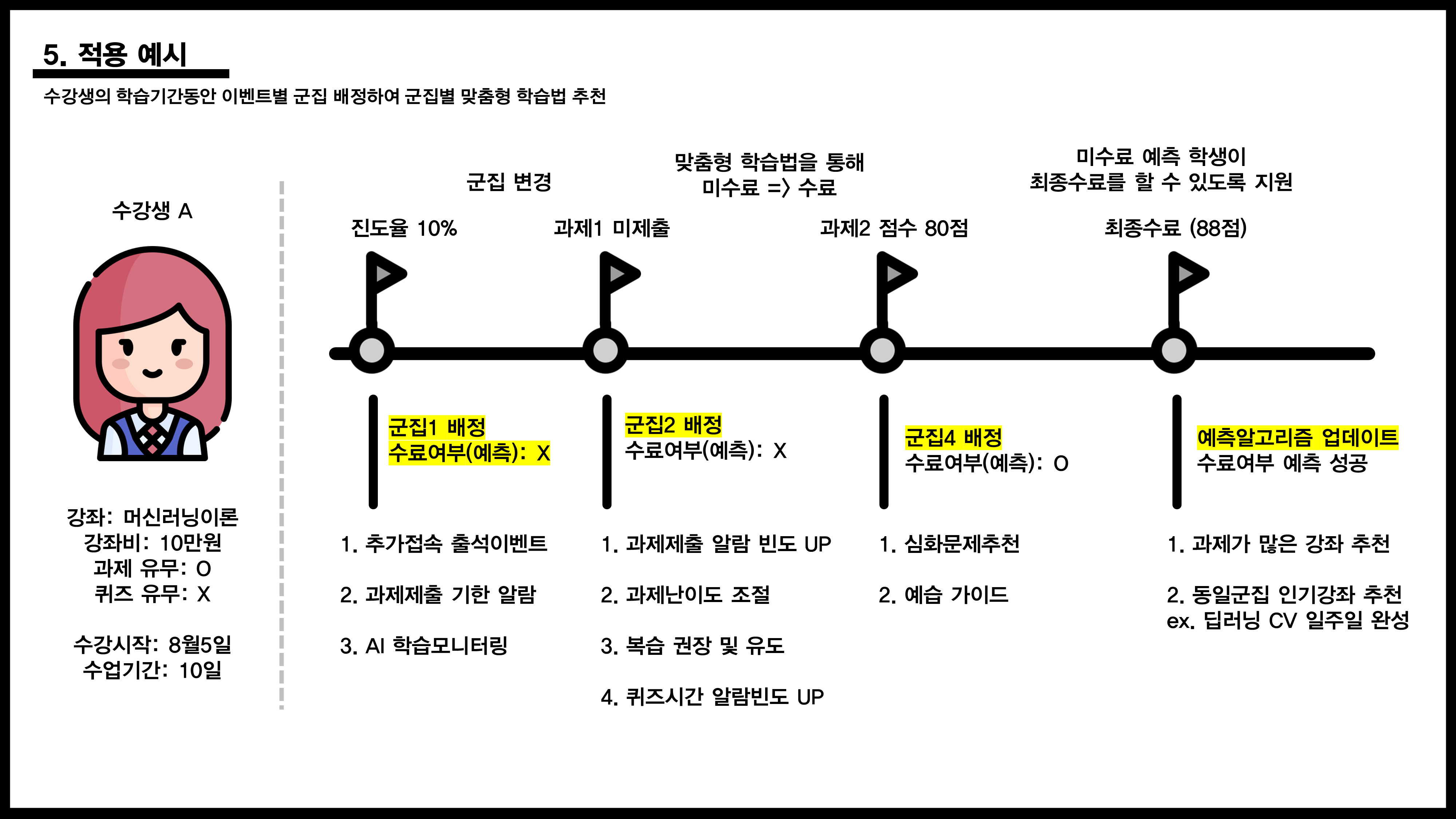
- 해당 장표는 실제 발표자료가 아닙니다.
7. 기대효과 및 향후 계획
7-1. 기대효과
1. 맞춤형 학습법을 통한 학습수준 향상
- 단순하게 상중하로 나누는 것이 아니라
학생들의 특징을 반영한 맞춤형 학습법 큐레이션 - 예측알고리즘과 군집화를 모두 사용하여 다각적인 접근
- 강좌별 Rule-Based -> 강좌 전체 대상 AI 대상화
2. 비인기 강좌 및 강사에 대한 분석 정확도 향상
- 데이터 합성 (SMOTETomek)으로 초반 데이터 부족 현상 보완
- MSE 14.64 => 11.01
7-2. 향후 계획
1. 주요변수 추가 수집 및 활용 제안
- 진도율, 강좌비용, 학습기간, 최종평가환산비율, 과제 여부 등
2. 강사 데이터 순차적 확보 후 모델링에 추가
- 강좌 정보가 주요변수였듯이, 강사의 데이터를 추가로 확보하여 활용한다면 보다 성능이 고도화할 수 있을 것으로 예상된다.
3. 공교육/사교육별 모델링 세분화
- 공교육과 사교육은 목적과 형태에 있어서 차이가 있기 때문에
학생들의 수강패턴이 상이할 것으로 예상되므로, 모델도 구분되어야 할 것이다.
8. Appendix
*목차만 제시하고, 실제 자료는 생략한다.
01 데이터
데이터(1) 변수 설명
데이터(2) 변수 매칭 (오픈데이터(온라인교육 수강패턴)와 크루디데이터 변수 매칭)
02 방법론 설명
(1) XGBosot, Catboost 장점 및 간단설명
(2) XGBoost 성능 고도화(Hyperparameter Tuning) 및 Tree 예시
(3) FAMD 시각화 및 수행근거
(4) KmeansClustering: 시각화 및 분류과정
(5) SMOTE-Tomek: SMOTE와 Tomek’s Link 결합
03 모델비교
(1) 수료여부 및 수료점수 모델별 기본 성능
(2) 변수조합별 모델 성능: 수료여부 및 수료점수 예측
(3) FADM 주성분 선택 근거
(4) 군집화 모델 비교 1) Distortion Score 2) Silhouette Score
04 군집별 특징표
(1) KMeans Clustering (3개)
(2) 최종군집 (5개)
05 군집 분류/ 수료여부 및 수료점수 예측 코드
06 Reference