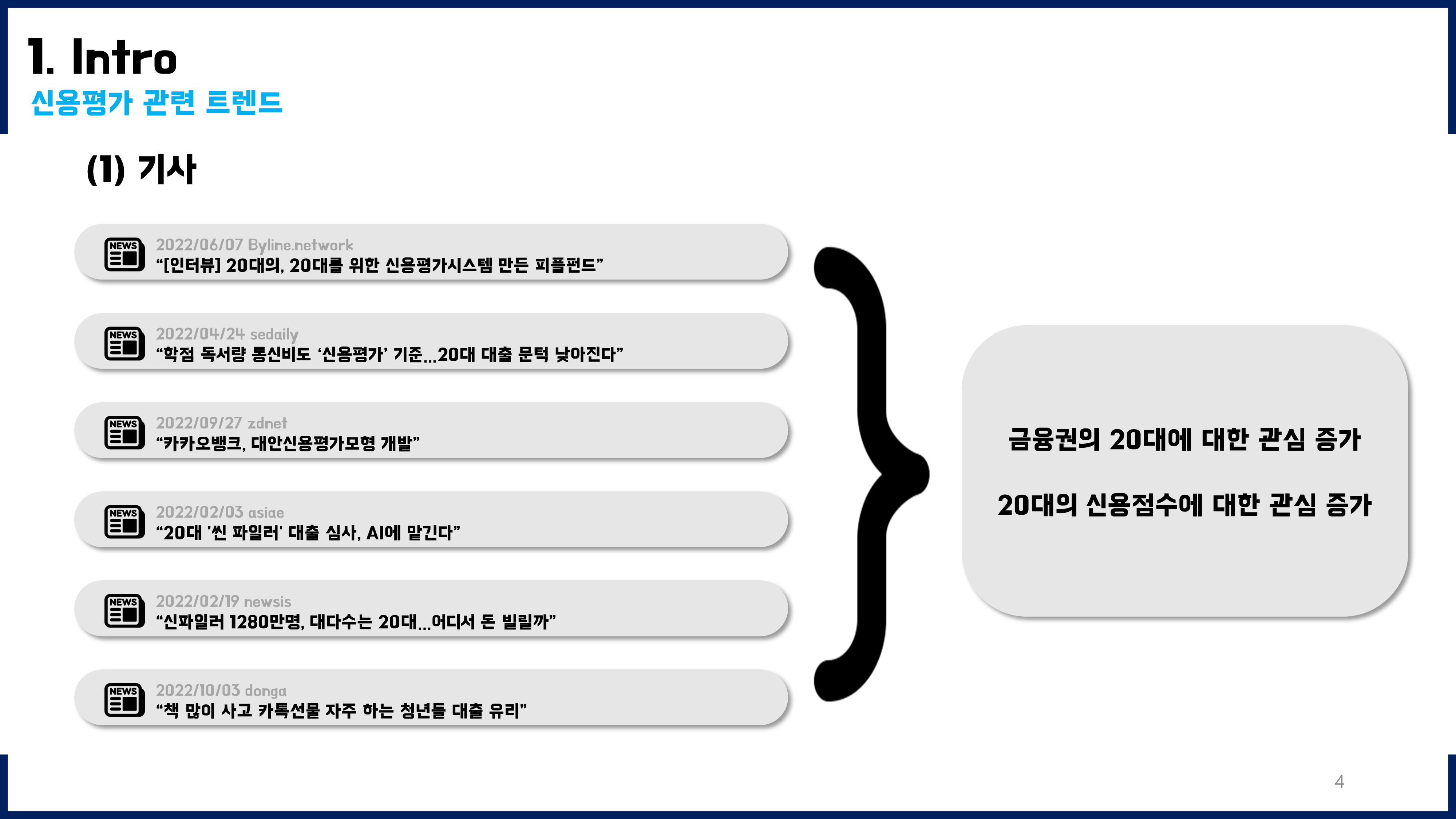
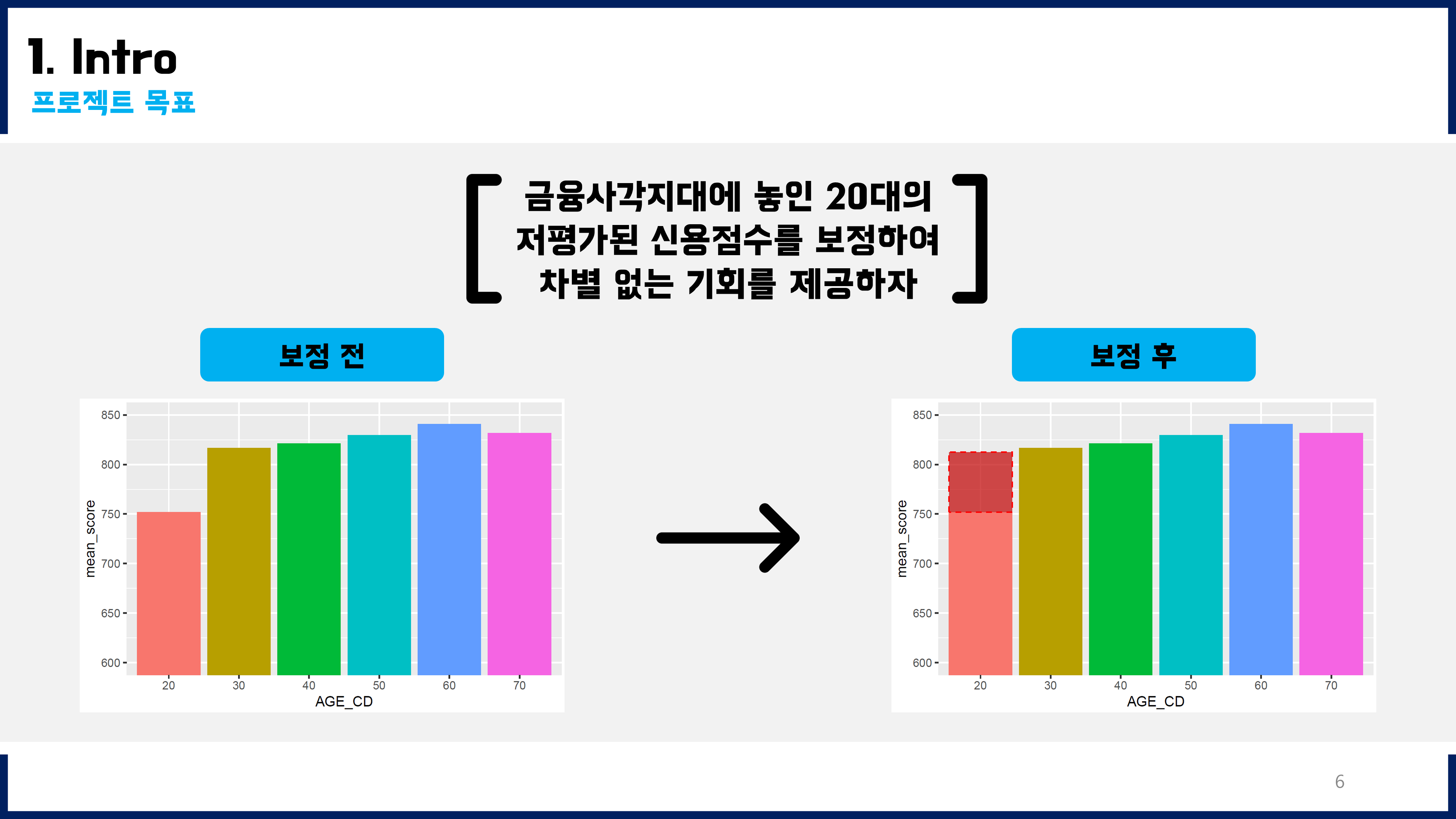
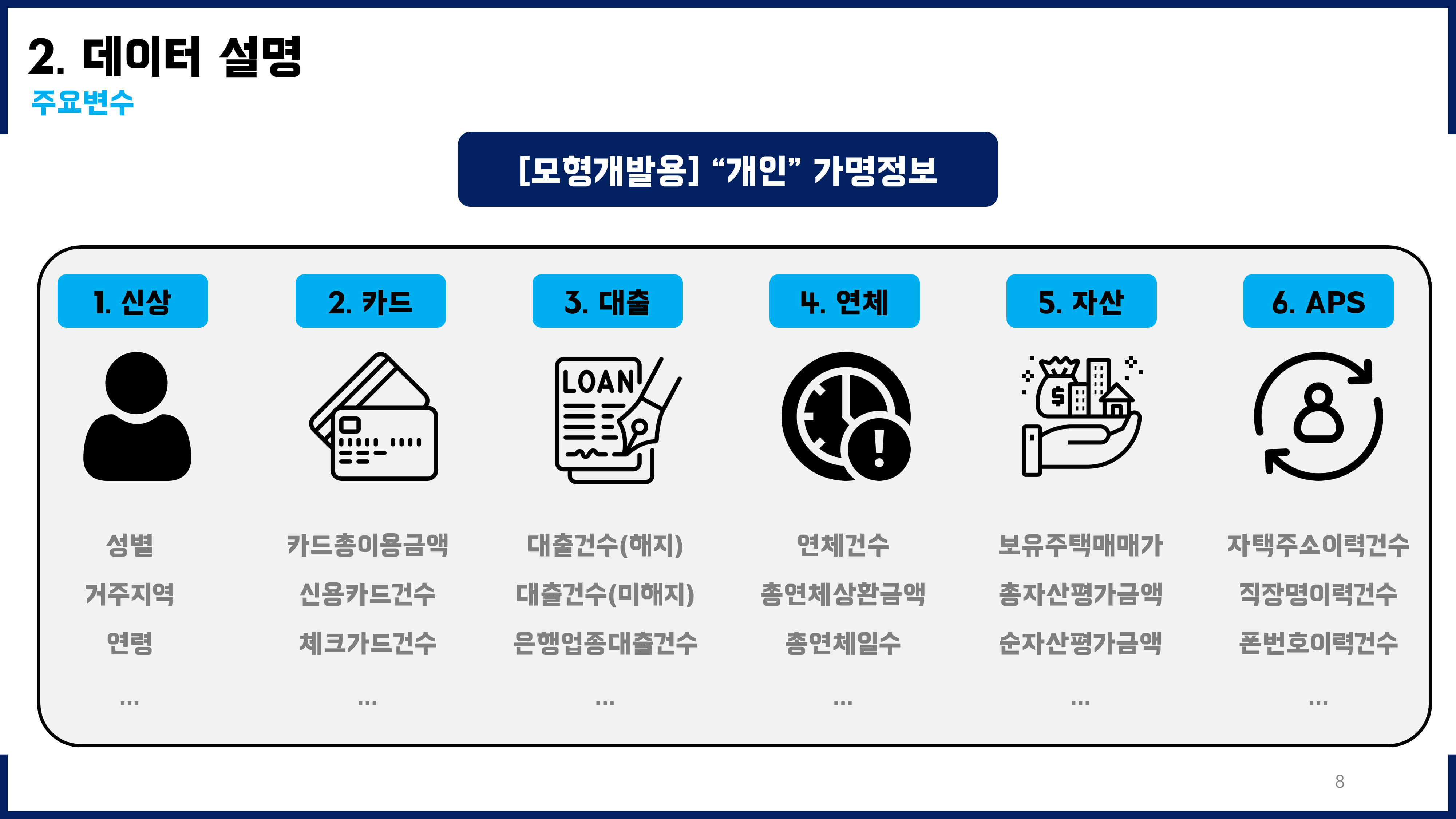
2030 개인신용평가모형 개발
- 분석기간: 2022 December ~ 2023 January
- 2022연세데이터사이언스경진대회에 참여하여 진행한 프로젝트이다.
- 팀원 간 정보 공유 및 기록을 위하여 노션 페이지를 만들어두었다.
1. Domain Knowledge
1-1. 금융리스크
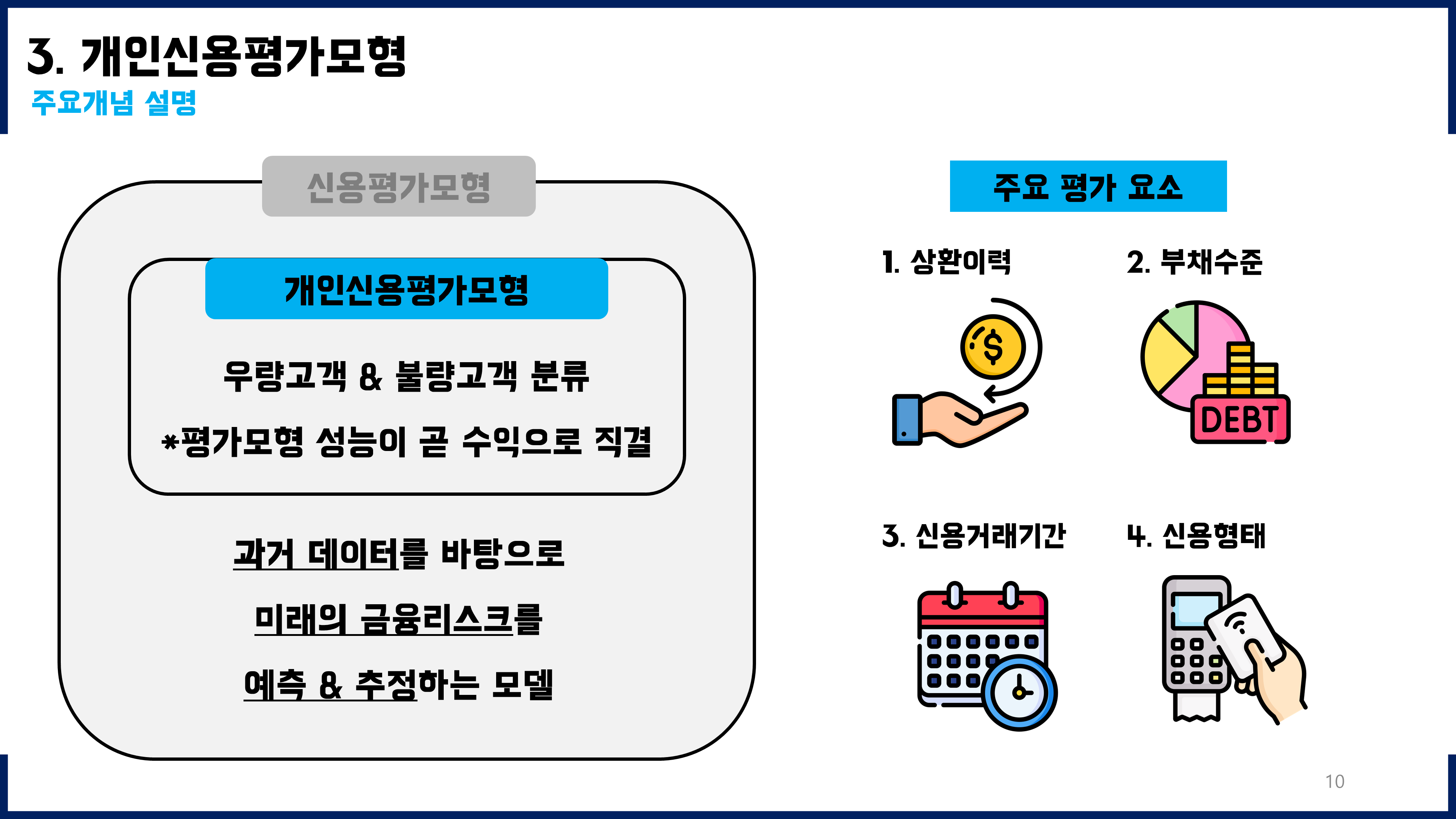
1-2. 개인신용평가모형
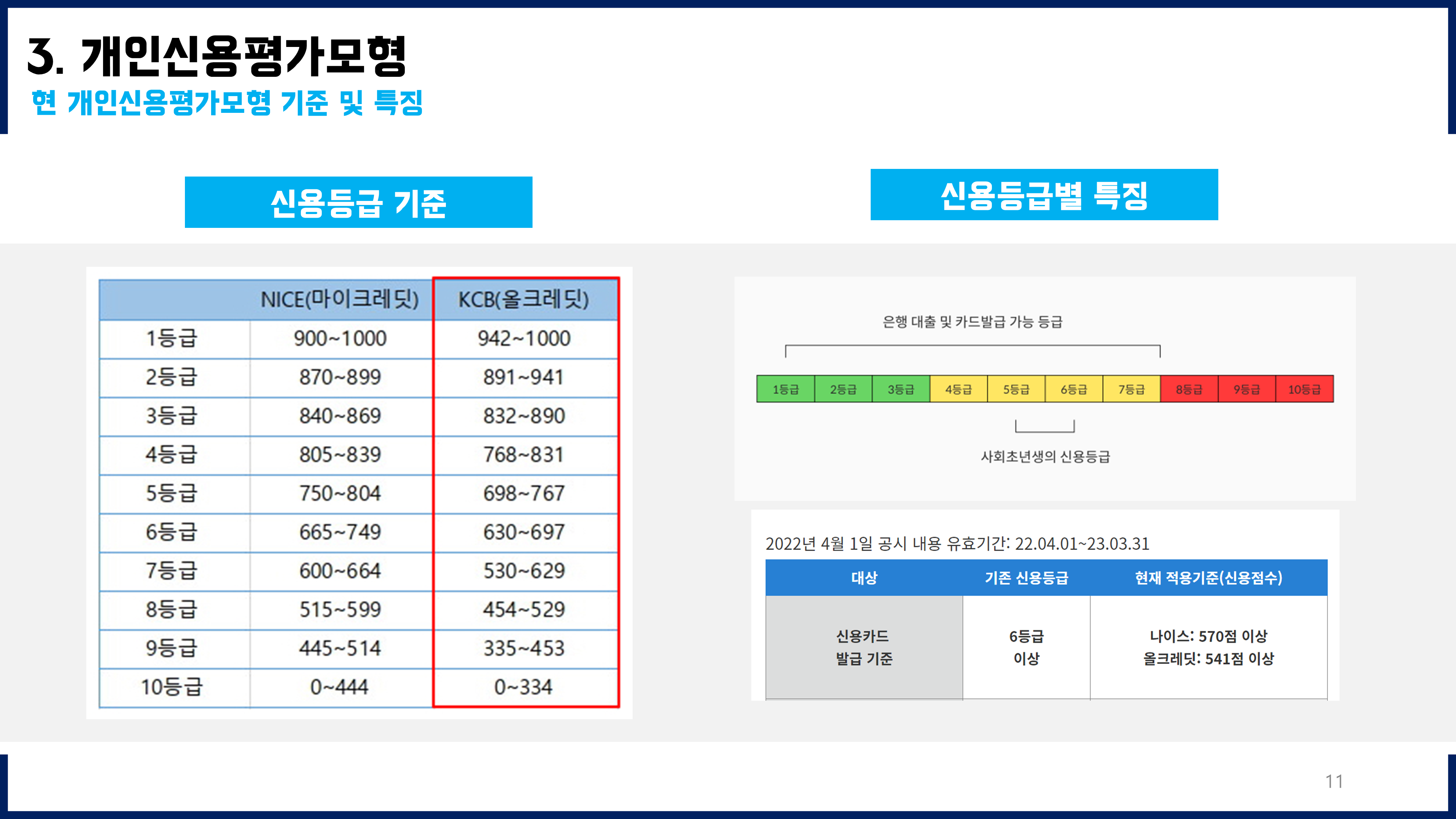
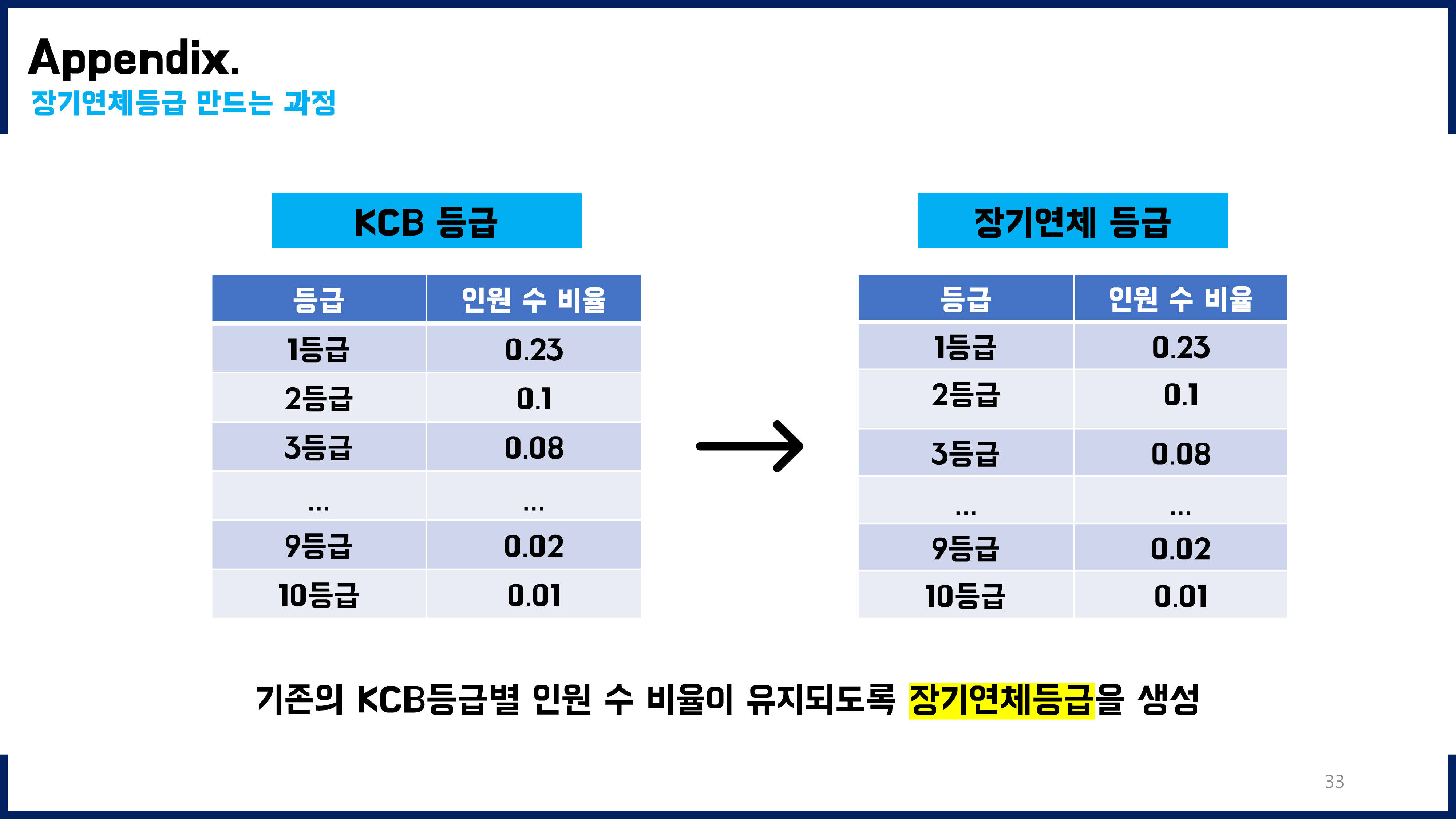
NICE평가정보 신용등급체계공시를 참고하였다.
—
2. What I Have Learned
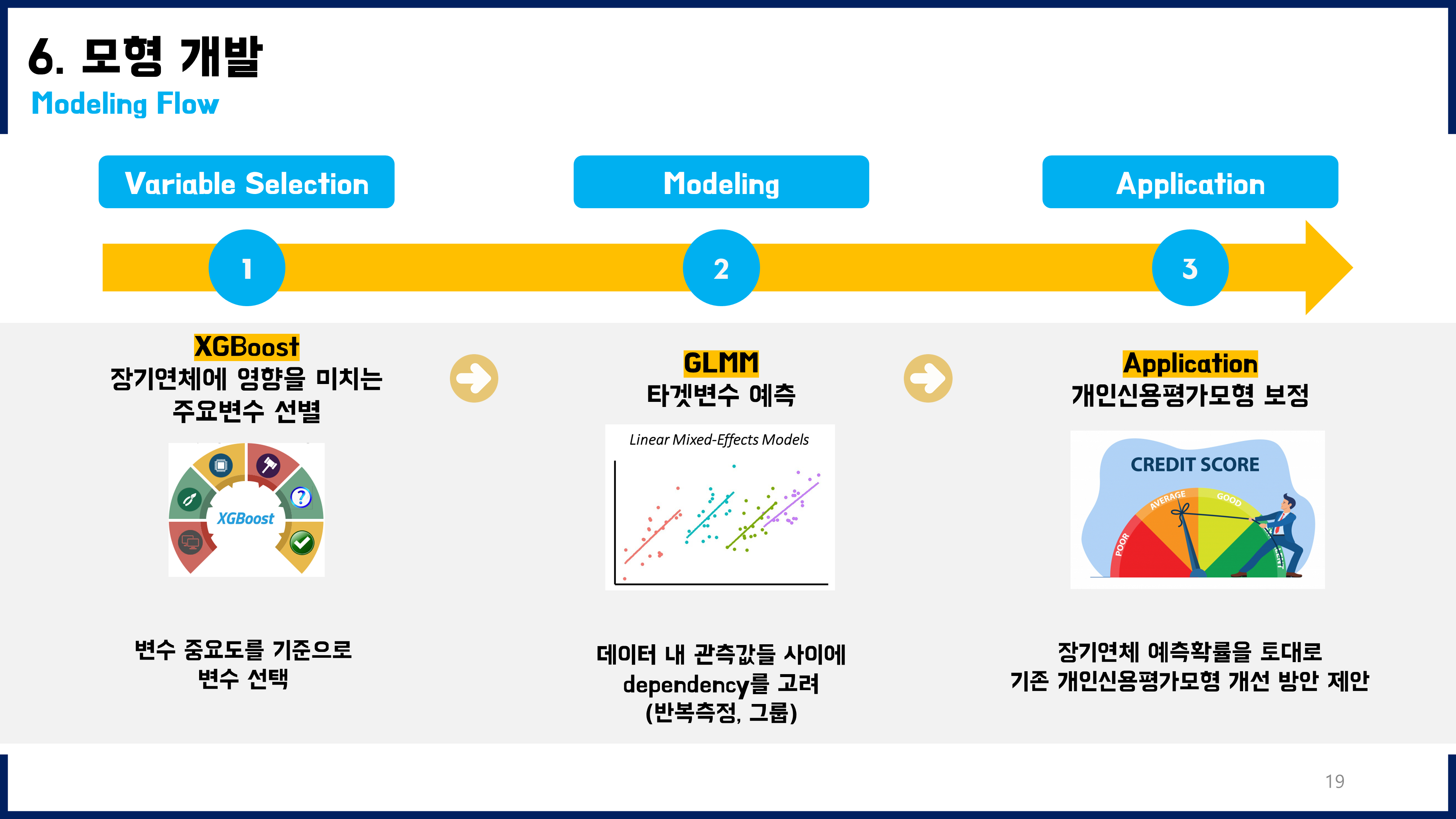
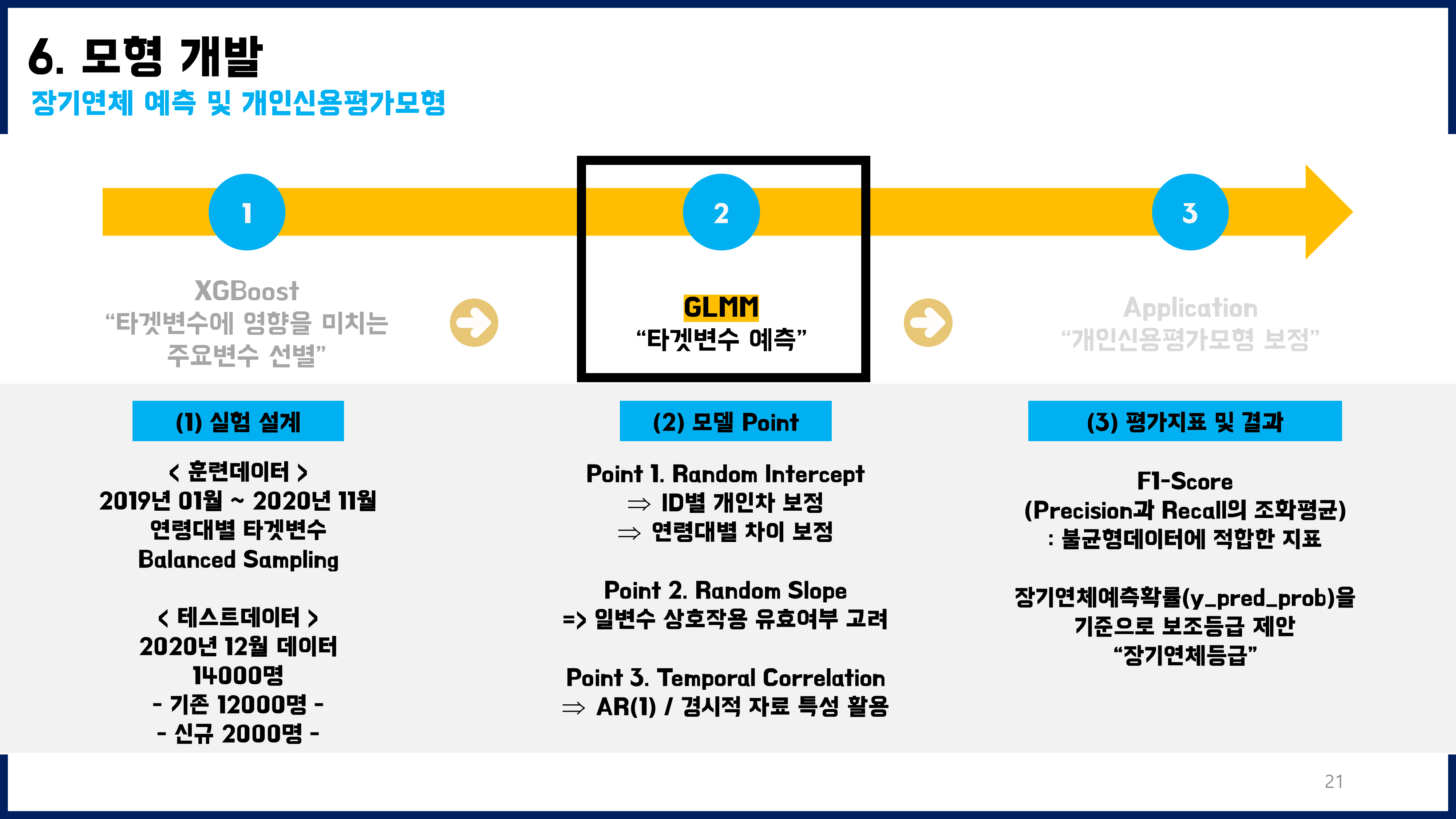
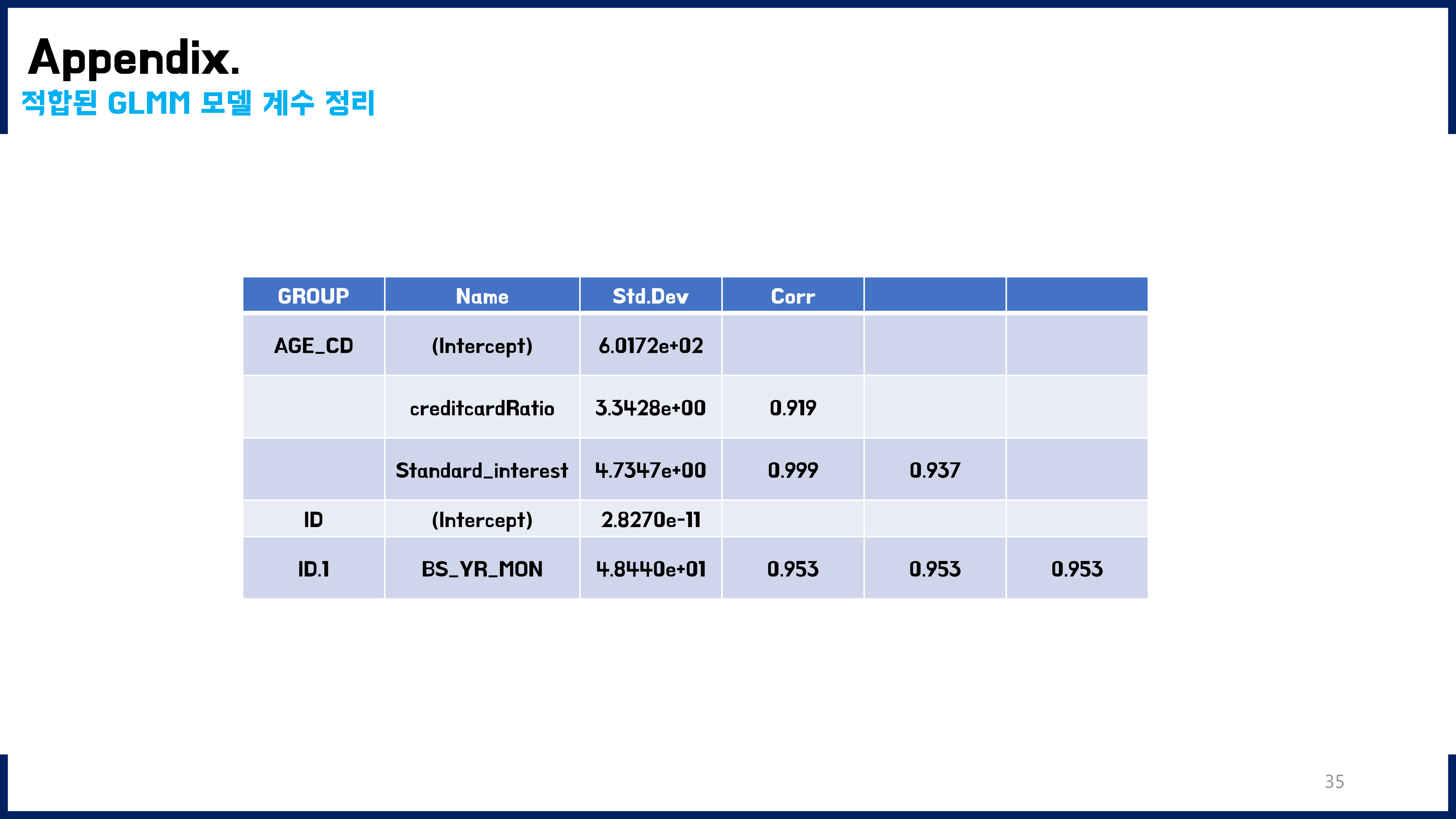
1. GLMM
Generalized Linear Mixed Model
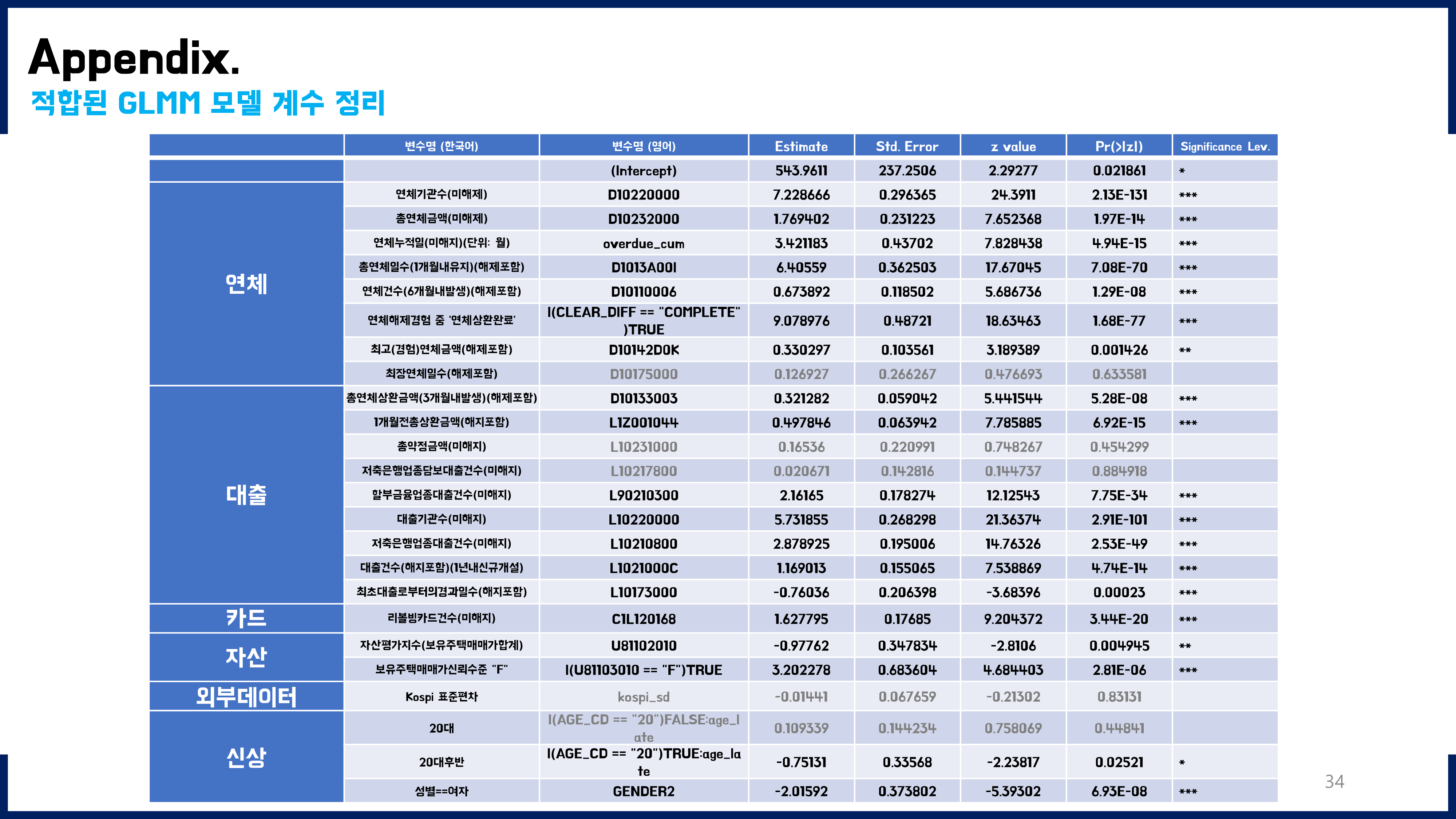
본 데이터는 36개월동안 매월말 반복측정된 패널데이터였다. 또한, 주제와 관련하여 연령대별 특징을 잘 보정해줄 필요가 있었기에 GLMM이 가장 적절한 모델이라고 판단하였다. R에는 nlme, lme4, brms 등 glmm을 구현하는 다양한 패키지들이 있다. 해당 패키지들을 모두 사용해보았는데, 이중에서 glmmTMB라는 패키지를 최종적으로 선택하게 되었다. 이 패키지를 사용한 이유는, temporal autocorrelation와 crossed random effect를 동시에 고려하면서 계산할 수 있는 패키지였기 때문이다. GLMM과 관련하여 공부한 내용은 노션 개인블로그 페이지에 정리해두었고, 참고한 자료는 해당 노션 페이지에 정리해두었다.
2. 빅데이터 활용 경험
3400만 행 x 153개 열의 데이터는 17GB가 넘는 큰 데이터.
만 명 내외의 샘플로 모델을 학습하더라도, 복잡한 모델의 경우에는 RAM 64GB의 데스크톱으로도 모델 학습 어려웠다.
이를 해소하기 위해서 sparse Matrix를 활용하는 방법을 고민해보고, 유의미한 sampling을 하는 방식에 대해서도 고민하는 등, 현실적인 측면에서의 어려움을 해소하는 방법들에 대해서도 고민해볼 수 있는 유의미한 프로젝트였다.
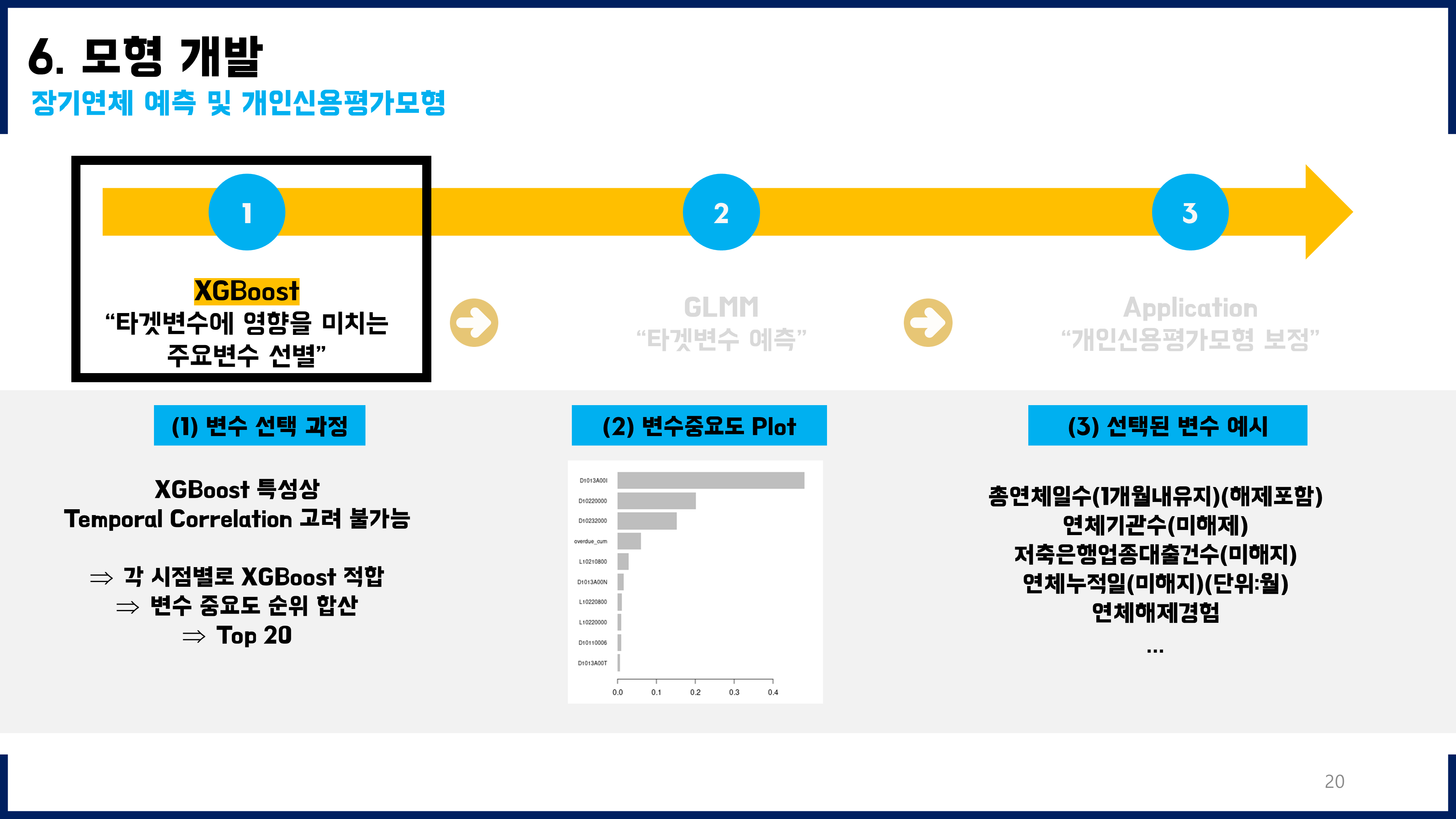
3. 불균형데이터의 중요성
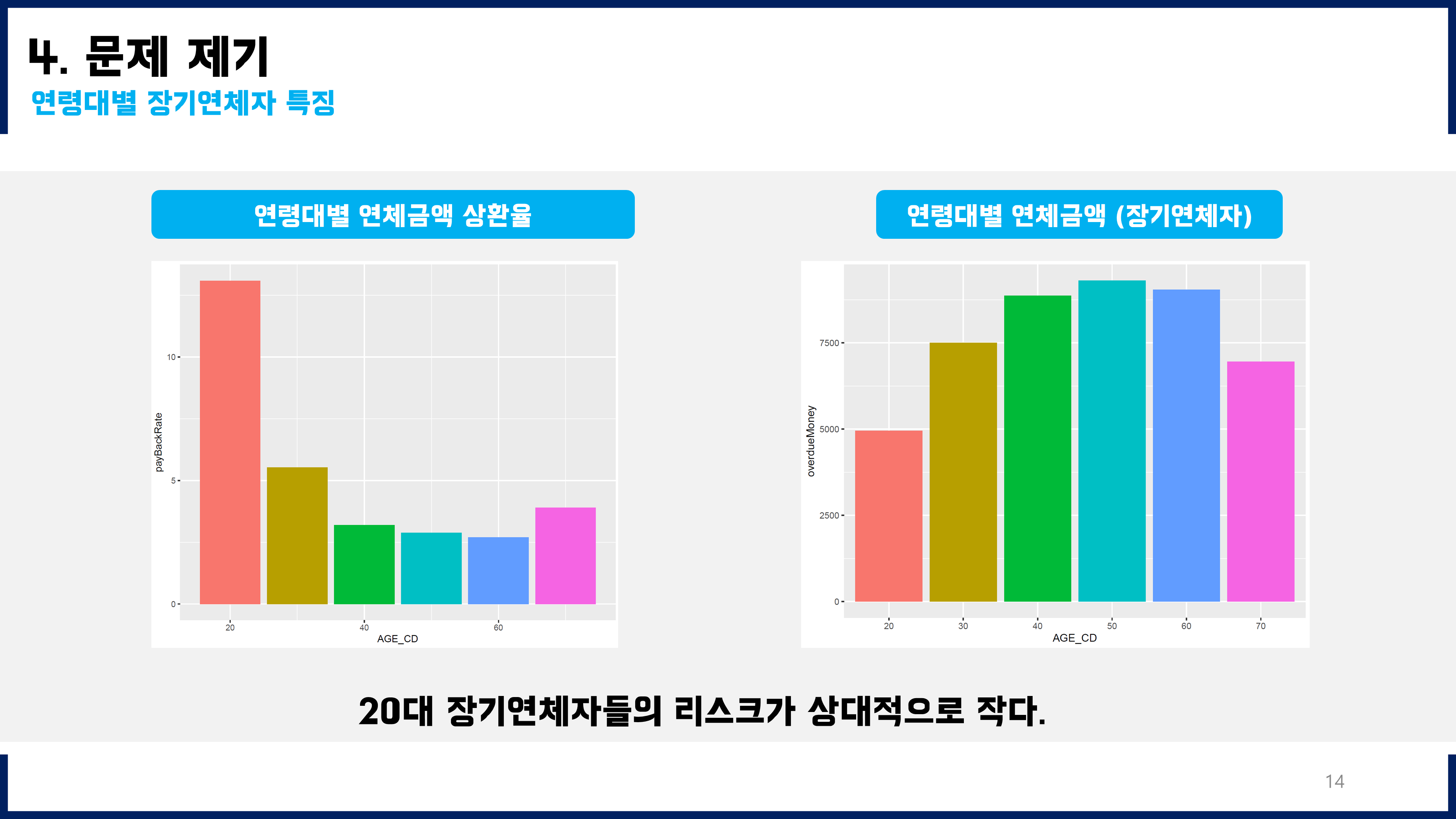
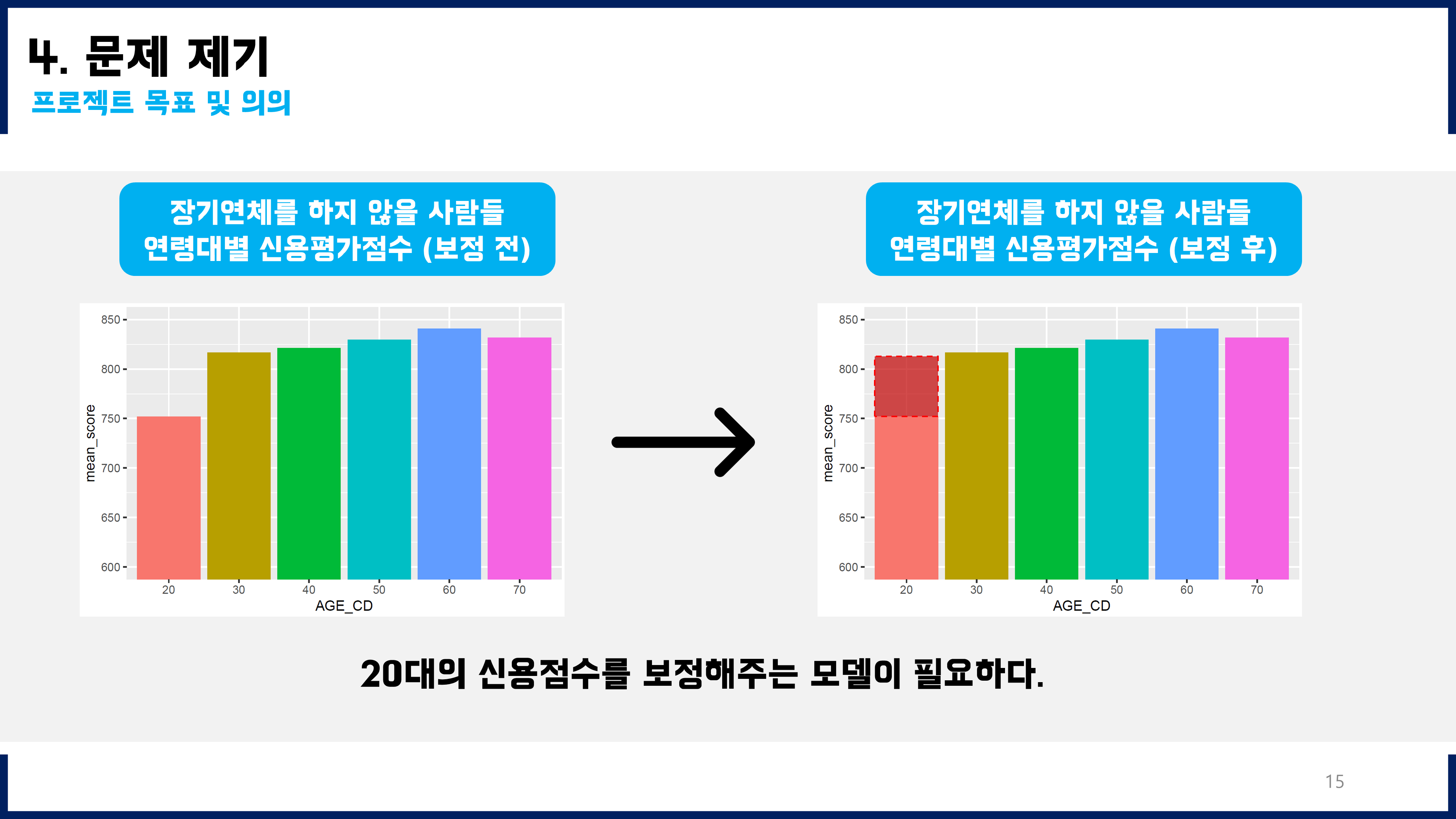
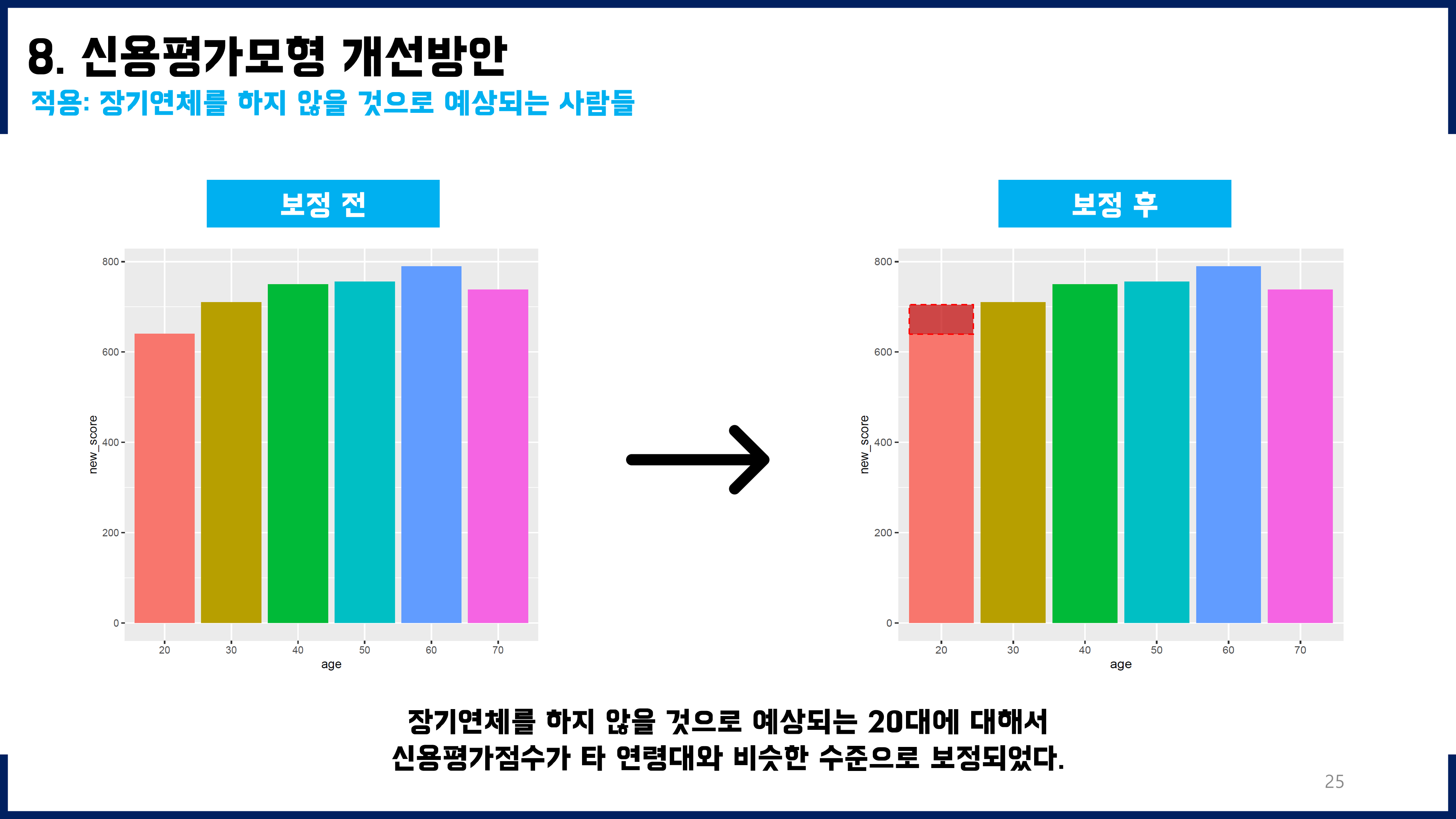
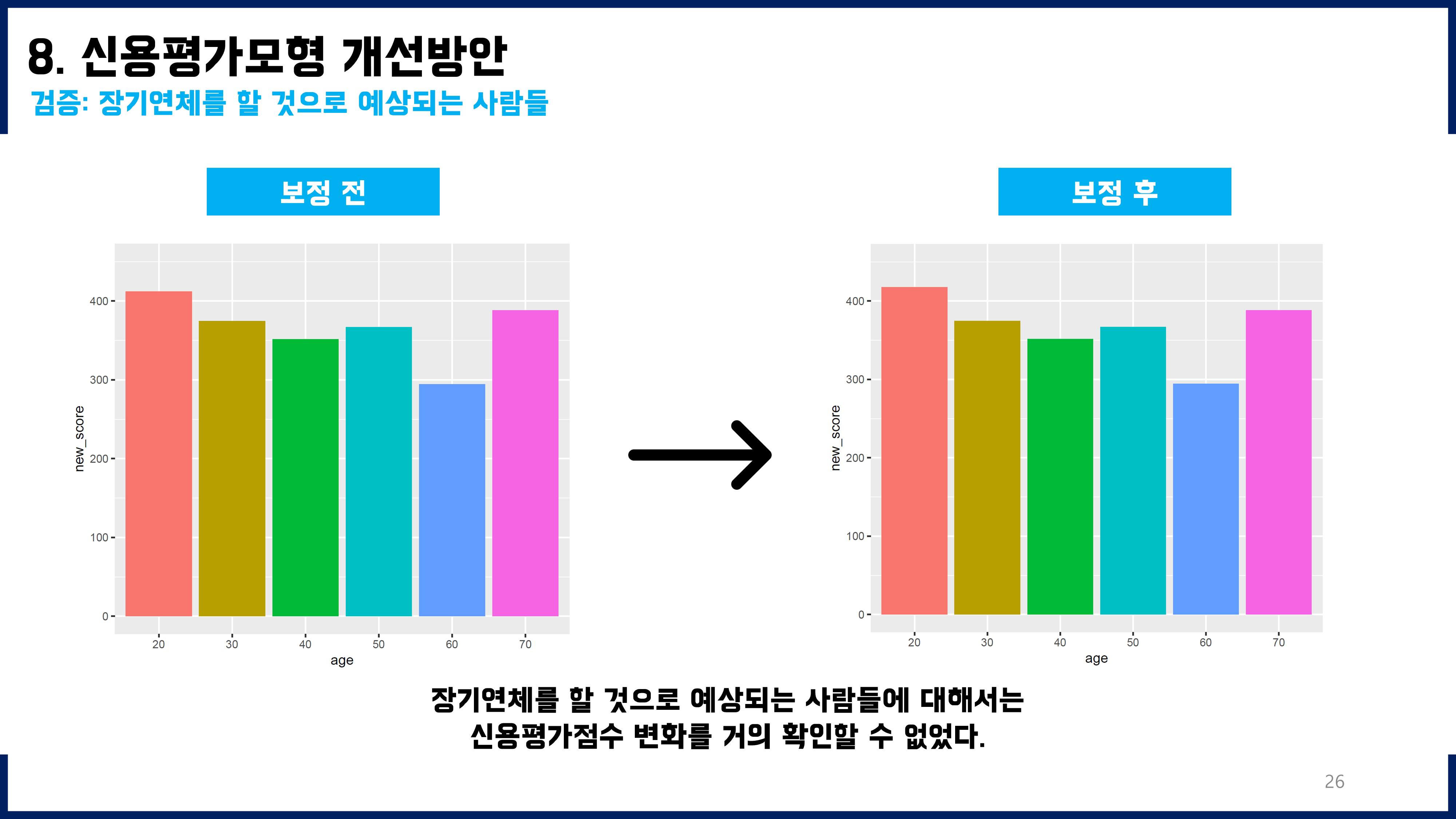
훈련용데이터에 연령대도 모두 2000명씩, 그리고 그 세부적인 구성도 Y=0과 Y=1를 각각 1000명씩 균형잡히게 넣어주었더니 성능이 향상되었다. 훈련용데이터의 불균형도를 해소하기 전에는 f1-score가 0.3~0.4 정도였는데, 불균형도를 해소한 뒤 적합하였을 때에는 f1-score를 0.65(신규), 0.91(기존)까지 향상시킬 수 있었다.
4. 상단코딩
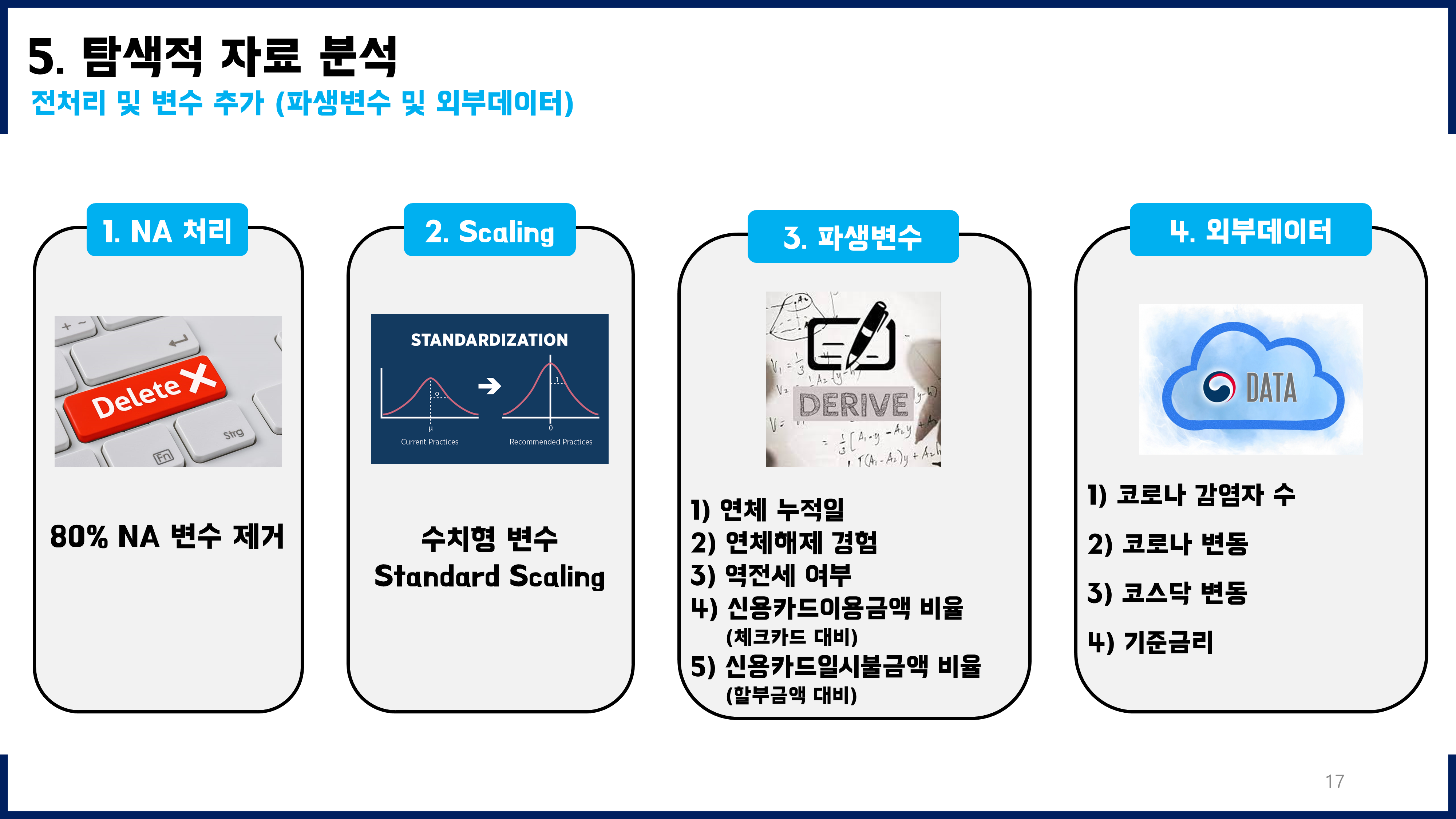
분석데이터는 수치형변수가 1% 값으로 상단코딩되어 있었다. 이에 따라 변수 간의 관계도 훼손되어있었고 그에 따른 파생되는 다양한 문제들이 있었다. 이를 되돌리기 위해서 다양한 노력을 했지만 쉽지 않았다. Domain Knowledge에 따라 유의미할 것으로 판단되는 변수들을 그래서 사용하지 못한 경우들이 있었는데, 추후 상단코딩 데이터를 분석하게 되거나 내가 직접 상단코딩 등으로 데이터의 보안을 수행하게 된다면 주의해야 할 점들을 배울 수 있는 프로젝트였다.
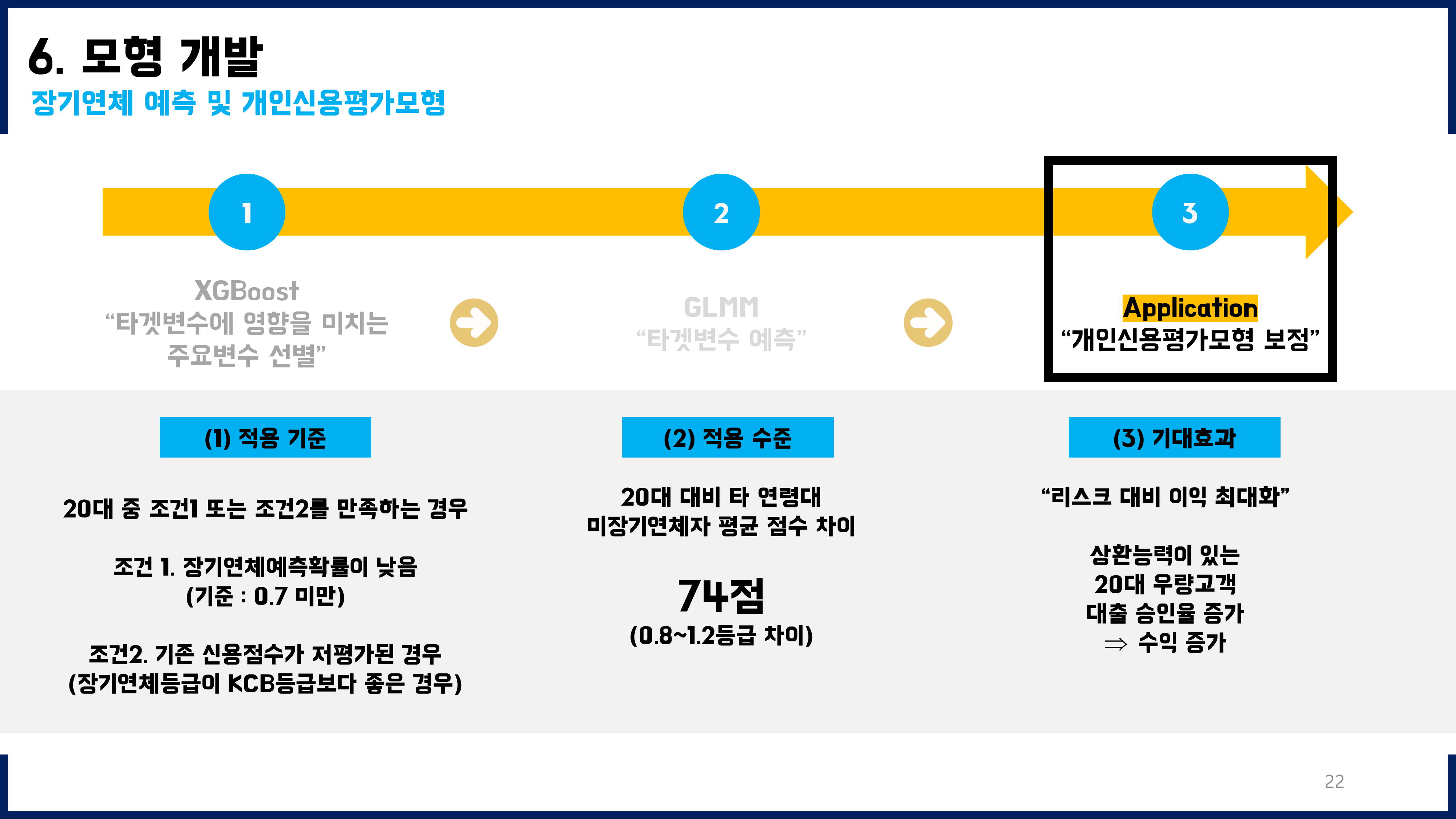
5. So WHAT?
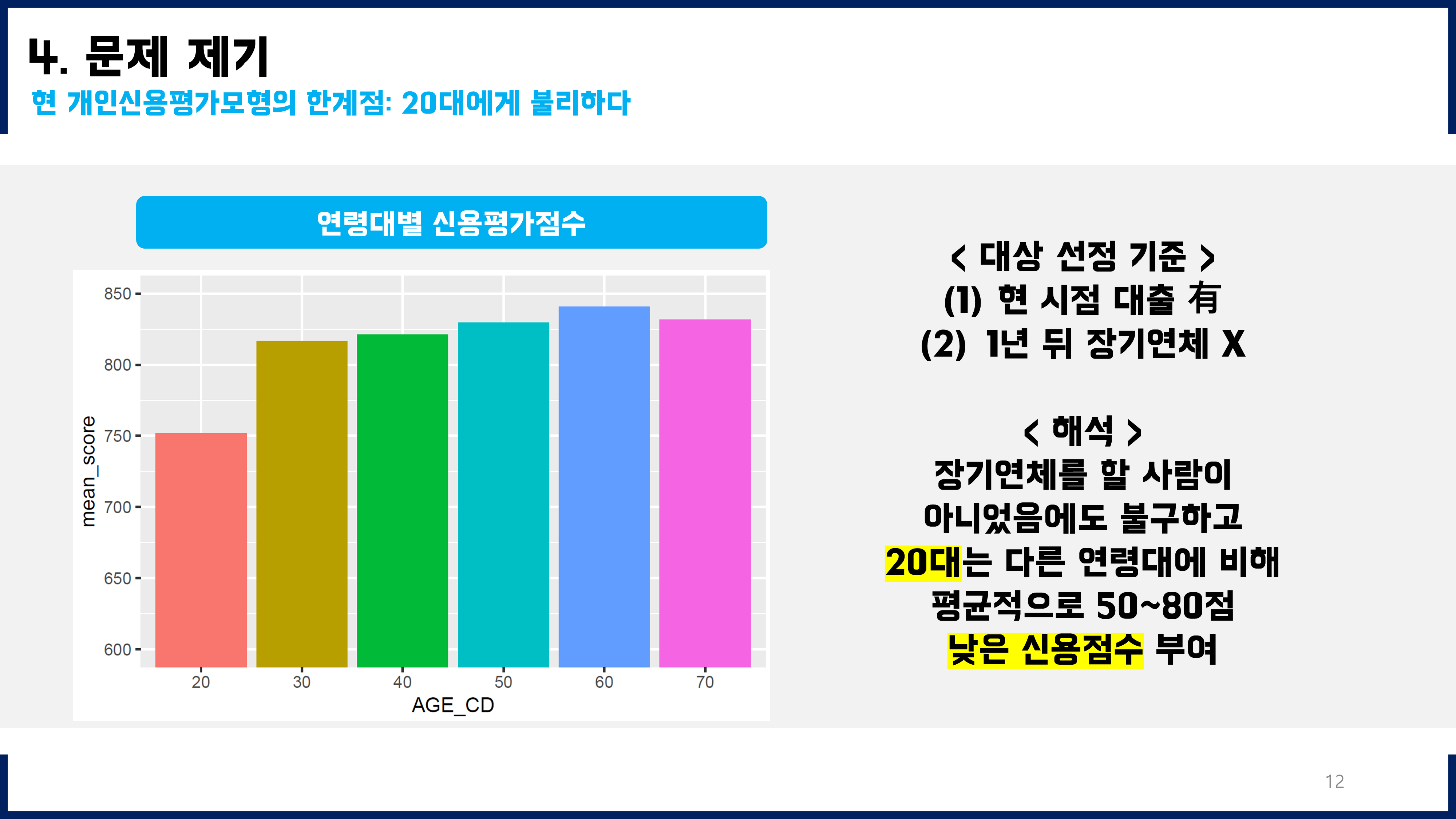
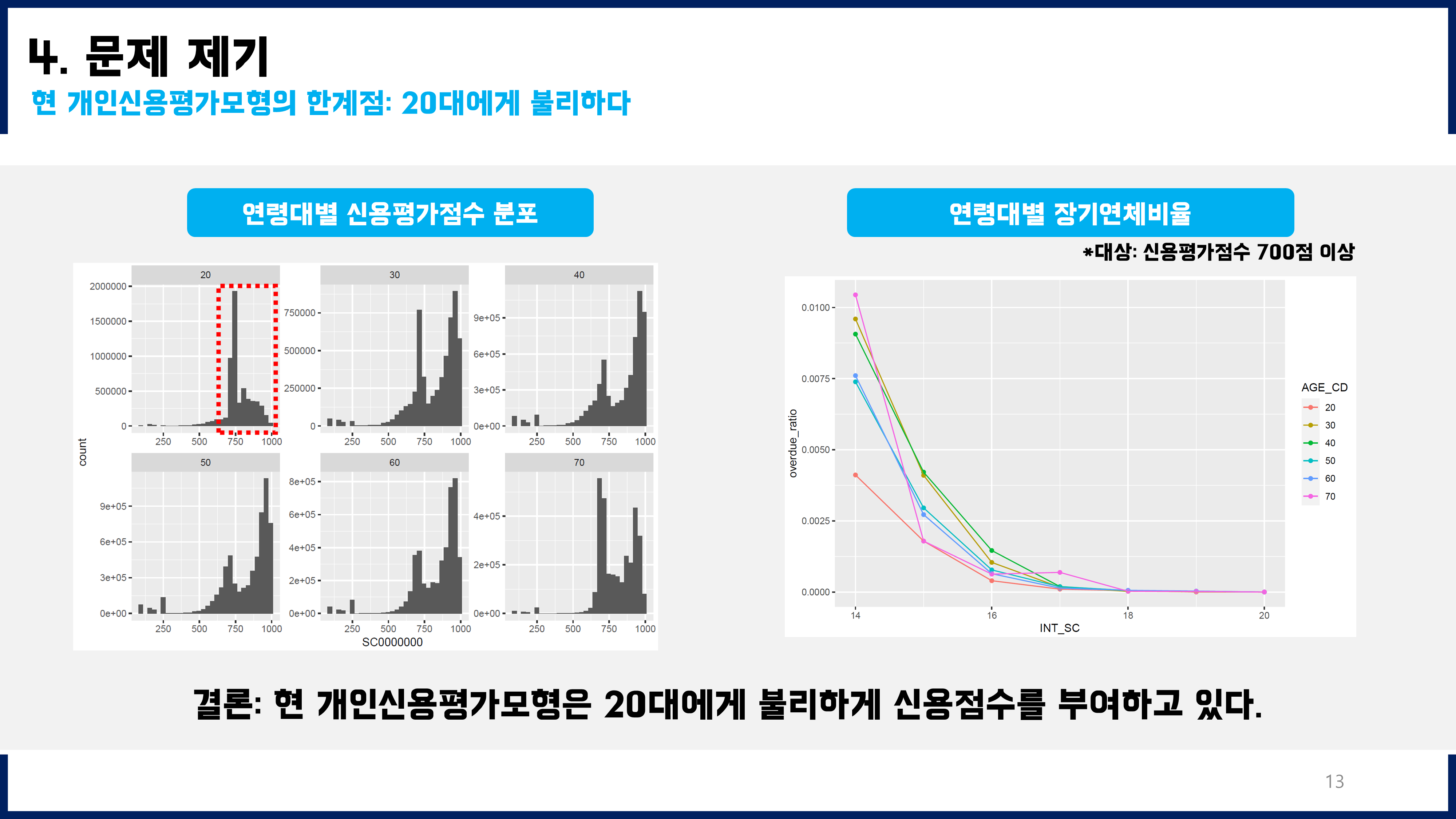
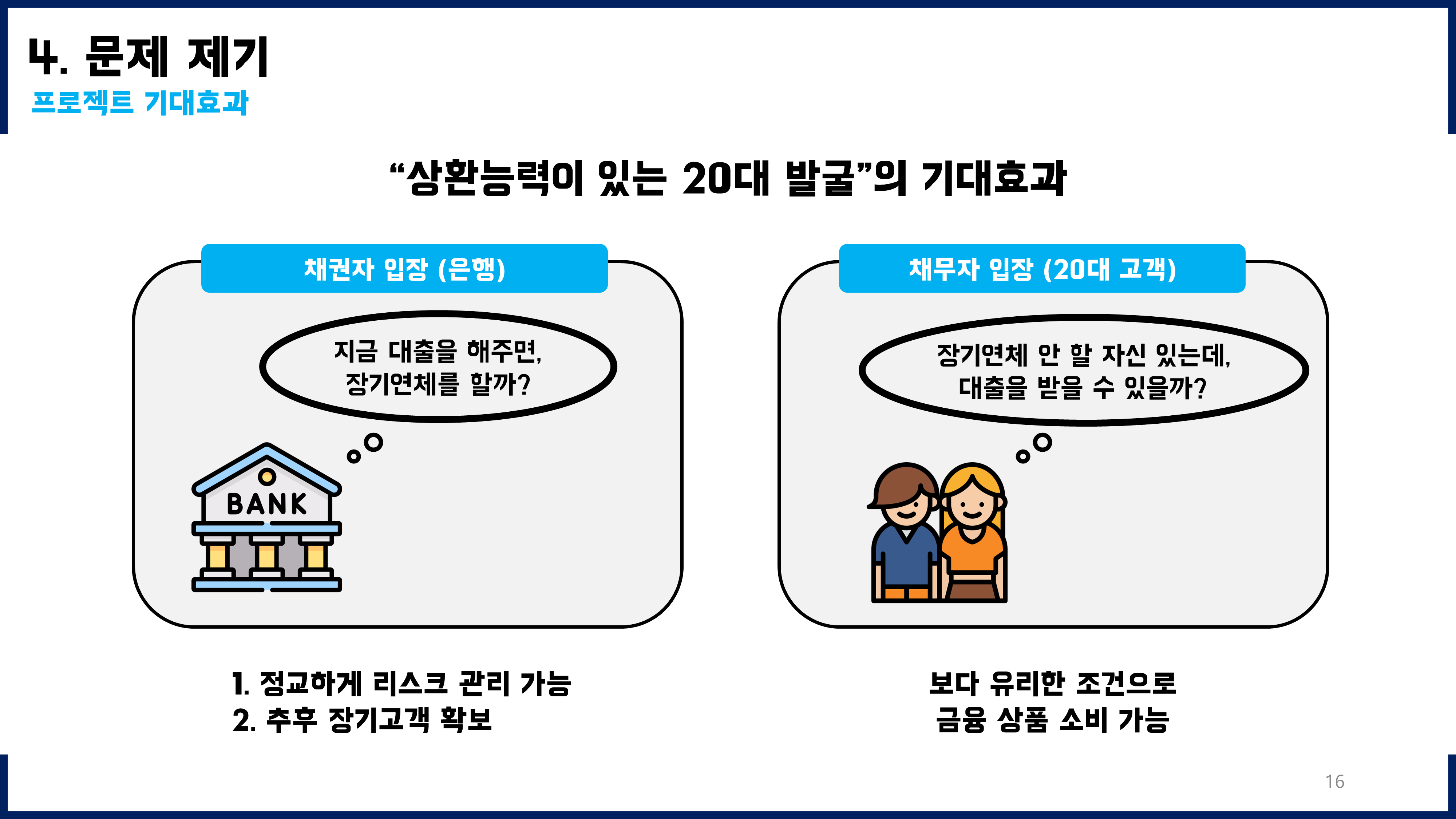
미래장기연체가능성을 예측하고, 그것을 바탕으로 최종적으로 어떻게 기존 모형에 활용할지 고민해보았다. 단순히 예측하는 데에서 그치는 것이 아니라, 이를 활용하여 현업에 적용하는 방안까지 고민해본 것이 좋은 경험이었다. 즉, 수동적인 데이터 분석이 아니라 분석결과를 어떻게 활용할 수 있고 그것의 긍정적인 가치(기대효과)까지 고민하고 기존 모델의 개선된 버전을 제안하는 데까지 이어질 수 있었다.
—
3. Presentation