Chapter 08.
Group Comparisons and Hierarchical Modeling
본 포스팅은 First Course in Bayesian Statistical Methods를 참고하였다.
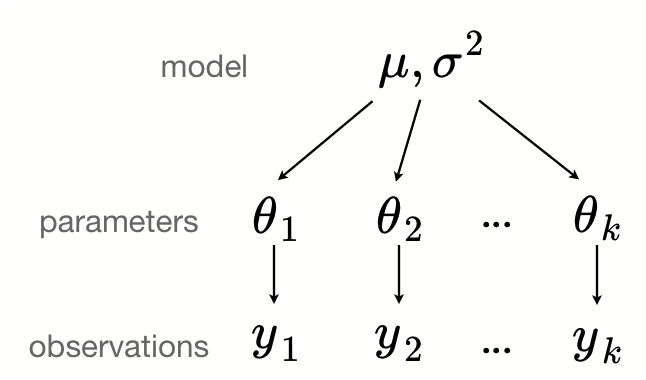
Hierarchical Model은 그룹 간 그리고 그룹 내 variability를 설정하는 데에 유용하다.
Hierarchical Model describes both with-in group and between-group variability.
Hierarchical Model은 베이즈 통계가 다른 응용분야에 널리 퍼져 사용되는 결정적 계기가 되었다. 그리고 위의 그림을 통해서 알 수 있듯이, 층이 여러 개 이기 때문에 복잡한 상황에서도 Estimation을 할 수 있다는 장점이 있다.
가장 큰 특징을 간단하게 요약해보자면, 여러 그룹끼리 서로 정보를 주고받는다는 점이다.
1. Exchangeability & De Finetti’s Theorem
이부분에 대해서는 Chapter2에서 이미 다룬 적은 있다. 그래도 이번 챕터의 논리전개에 대해서 정당성을 부여해주기 때문에 한 번 더 복습해보도록 하겠다. 우선 Exchangeability는 다음과 같이 쓸 수 있다.
$$p(y_1, ..., y_n) = p(y_{\pi_{1}}, ..., y_{\pi_{n}})$$
그리고 De Finetti’s Theorem은 exchangeability가 만족되면, Conditional Independence를 따른다는 것이었다. (참고로, 그 역은 자명하다.) 이때 조건으로는 small sample from large population이라고 한다. (자세한 것은 FCB를 읽어보자.)
2. Hierarchical Beta-Binomial
2-1. Posterior 종류 정리
Joint Posterior
$$\begin{align} p(\theta,\psi |y) &\propto p(y|\theta, \psi) \ p(\theta, \psi) \\ &= p(y|\theta) \ p(\theta, \psi) \\ &= p(y|\theta) \ p(\theta| \psi) \ p(\psi) \end{align}$$
Conditional Posterior
$$\begin{align} p(\theta | \psi, y) &\propto p(y, \psi|\theta) \ p(\theta) \\ &= p(y|\theta,\psi) \ p(\psi|\theta) \ p(\theta) \\ &= p(y|\theta) \ p(\theta, \psi) \\ &= p(y|\theta) \ p(\theta| \psi) \ p(\psi) \end{align}$$
Joint Posterior와 Conditional Posterior 각각의 마지막끼리 같다는 사실에 주목해보자.
Marginal Posterior
$$p(\psi|y) = \int_\Theta p(\theta, \psi | y)d\theta \\ p(\psi|y) = \frac{p(\theta,\psi|y)}{p(\theta|\psi, y)}$$
둘 중 편한 것으로 계산한다.
2-2. 간단 정리
$$p(\theta, \alpha, \beta|y) \propto p(\alpha,\beta) \ \prod_{j=1}^{m}\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta_j^{\alpha-1}(1-\theta_j)^{\beta-1} \ \prod_{j=1}^{m}\theta_j^{y_j}(1-\theta_j)^{n_j-y_j}$$
3층: hyperprior $\psi$
2층: $\theta_j|\psi \sim Beta(\alpha,\beta)$
1층: $y_j|\theta_j \sim Binom(n_j, \theta_j)$
2-3. hyperprior는 어떻게 주어야 할까?
결론부터 말하자면,
$$p(\alpha, \beta) \propto (\alpha+\beta)^{-\frac{5}{2}}$$
이렇게 준다고 한다. 해당 수식에 대한 그래프는 아래와 같은데, 시각적으로 uninformative에 가깝다는 것을 알 수 있다.
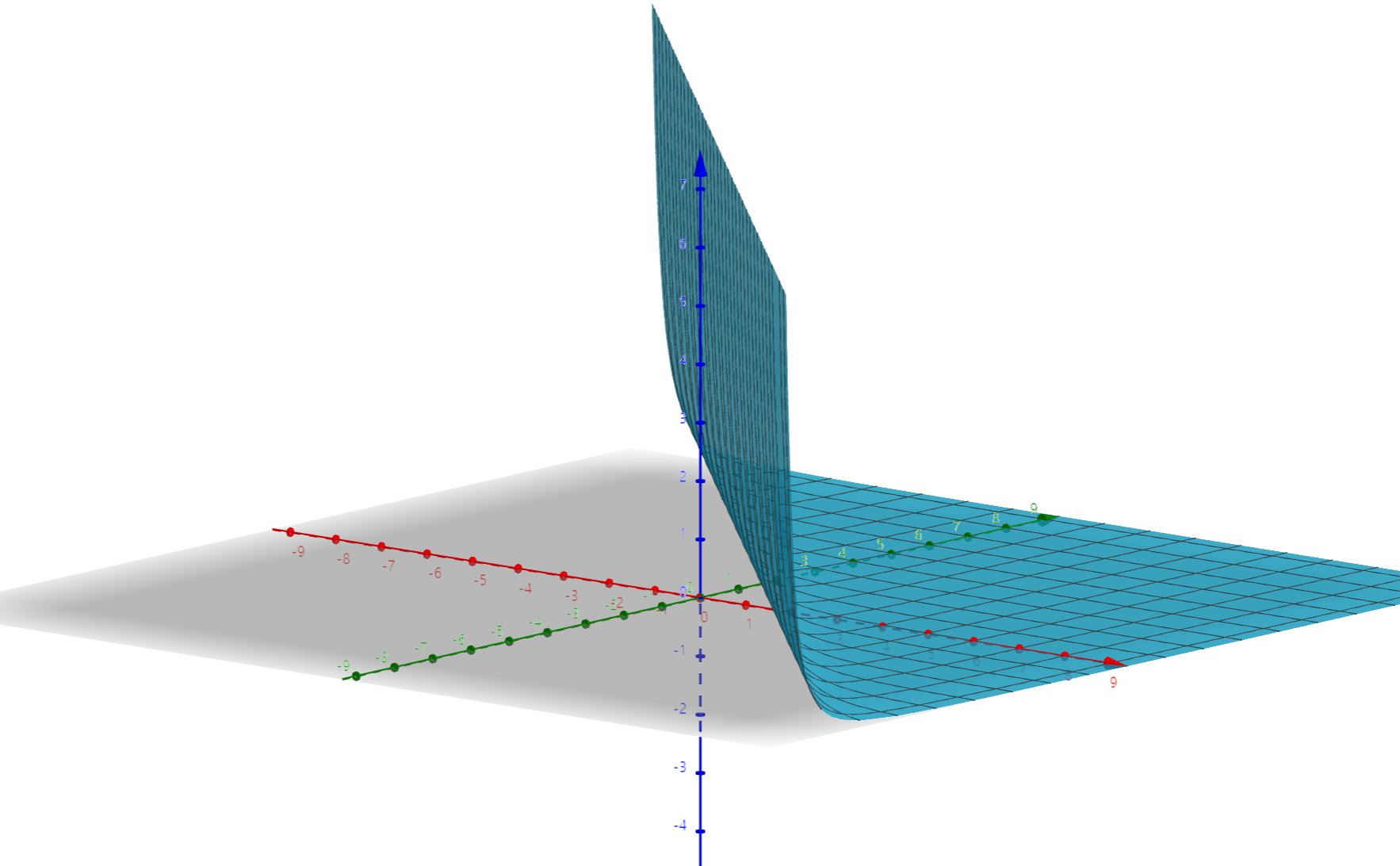
이는 원래는 아래와 같은 형태였다.
$$p\Big(log\frac{\alpha}{\beta}, (\alpha+\beta)^{-\frac{1}{2}}\Big) \propto 1$$
변수변환을 통해 유도하는 과정은 변수변환 포스팅에 자세하게 설명되어 있다. 그래서 결론적으로 아래와 같이 쓸 수 있다.
$$\rightarrow p(\theta, \alpha, \beta|y) \propto (\alpha+\beta)^{-\frac{5}{2}} \ \prod_{j=1}^{m}\frac{\Gamma(\alpha+\beta)}{\Gamma(\alpha)\Gamma(\beta)}\theta_j^{\alpha-1}(1-\theta_j)^{\beta-1} \ \prod_{j=1}^{m}\theta_j^{y_j}(1-\theta_j)^{n_j-y_j}$$
2-4. 예시
FCB 책에 나온 종양 쥐(Rat Tumor) 예시를 살펴보자.

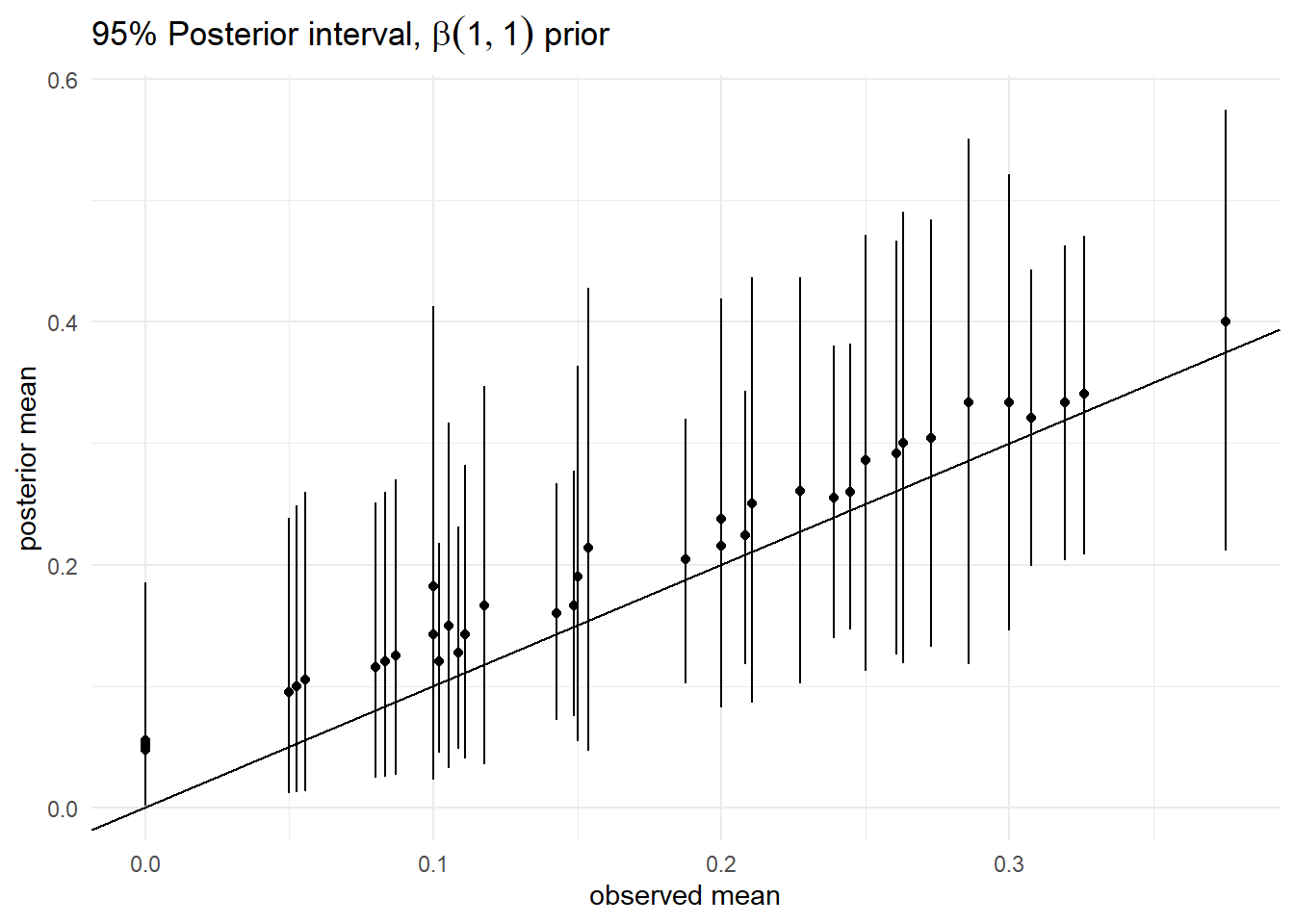
1) 95% Posterior interval
|
|
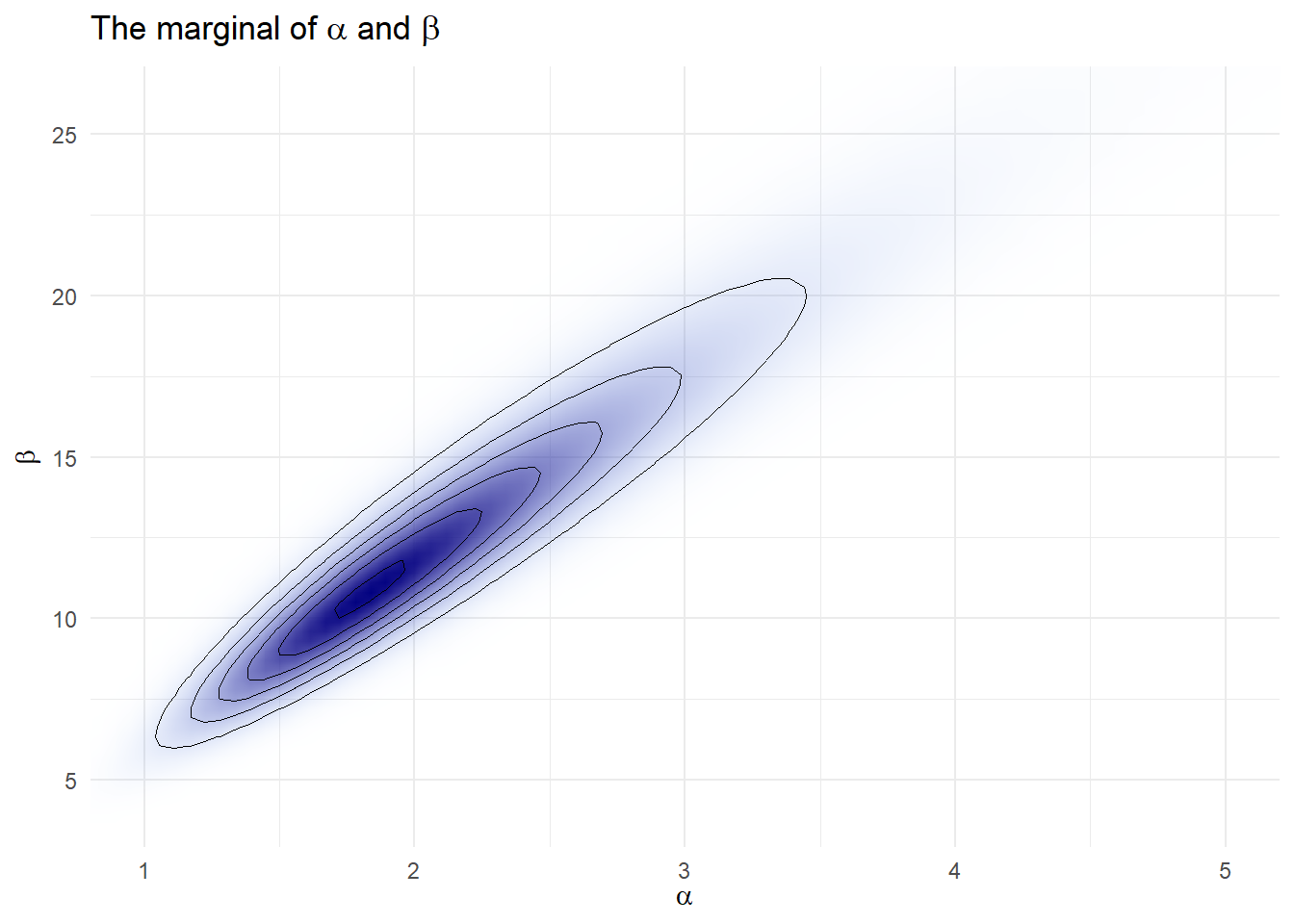
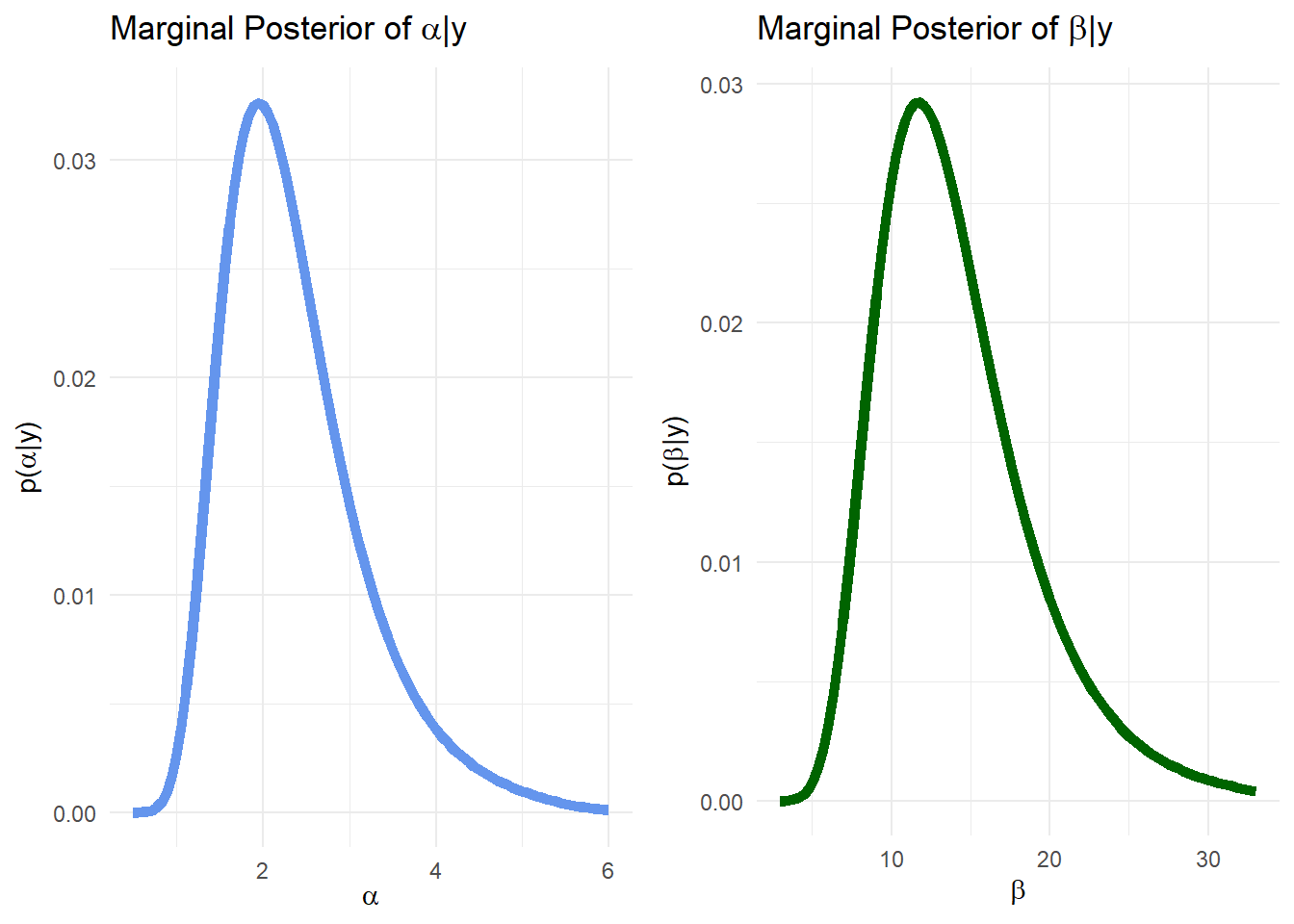
2) Marginal Distribution of alpha & beta
|
|
|
|
## `summarise()` ungrouping output (override with `.groups` argument)
|
|
## `summarise()` ungrouping output (override with `.groups` argument)
|
|
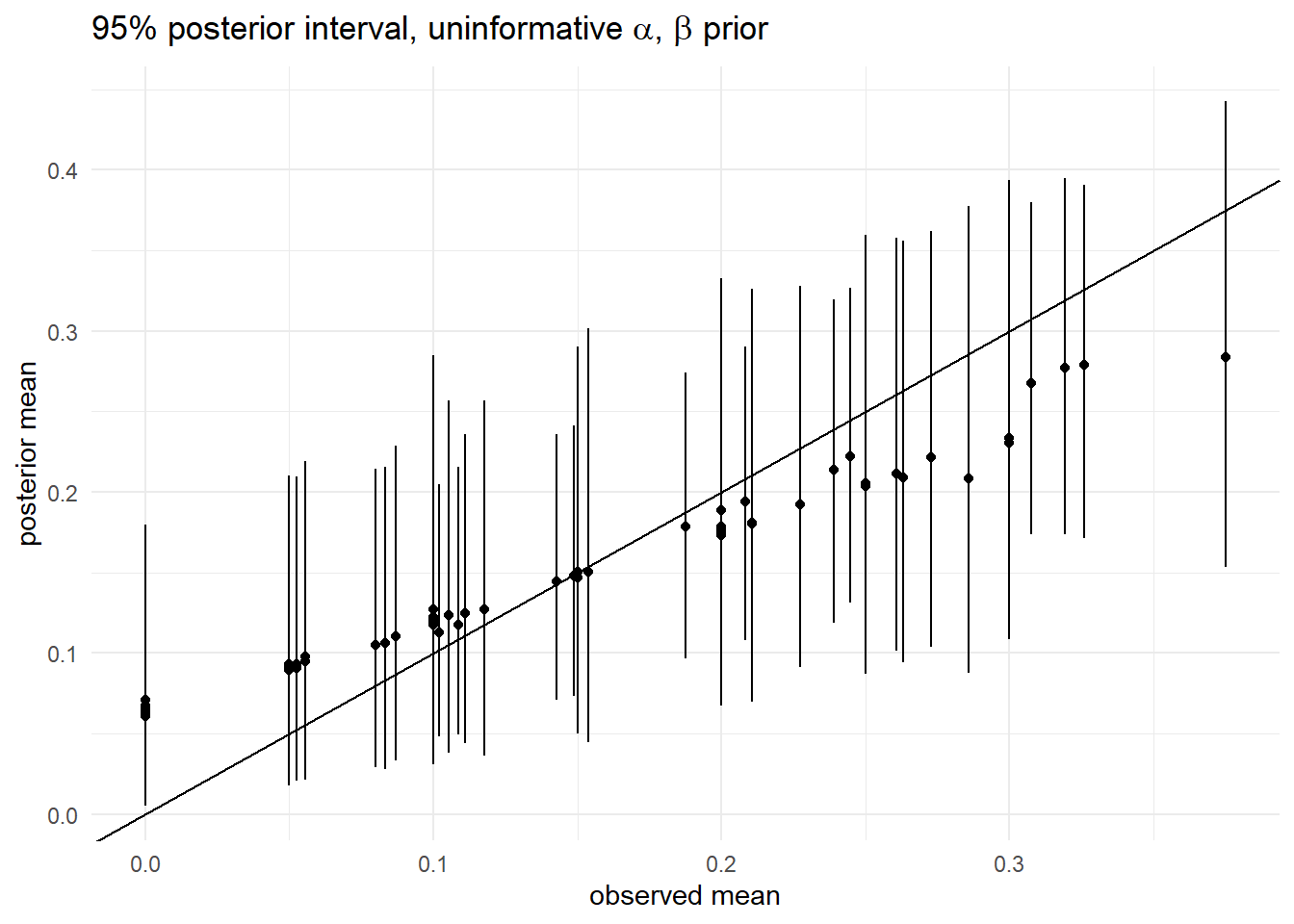
3) 95% posterior interval, uninformative prior($\alpha, \beta$)
|
|
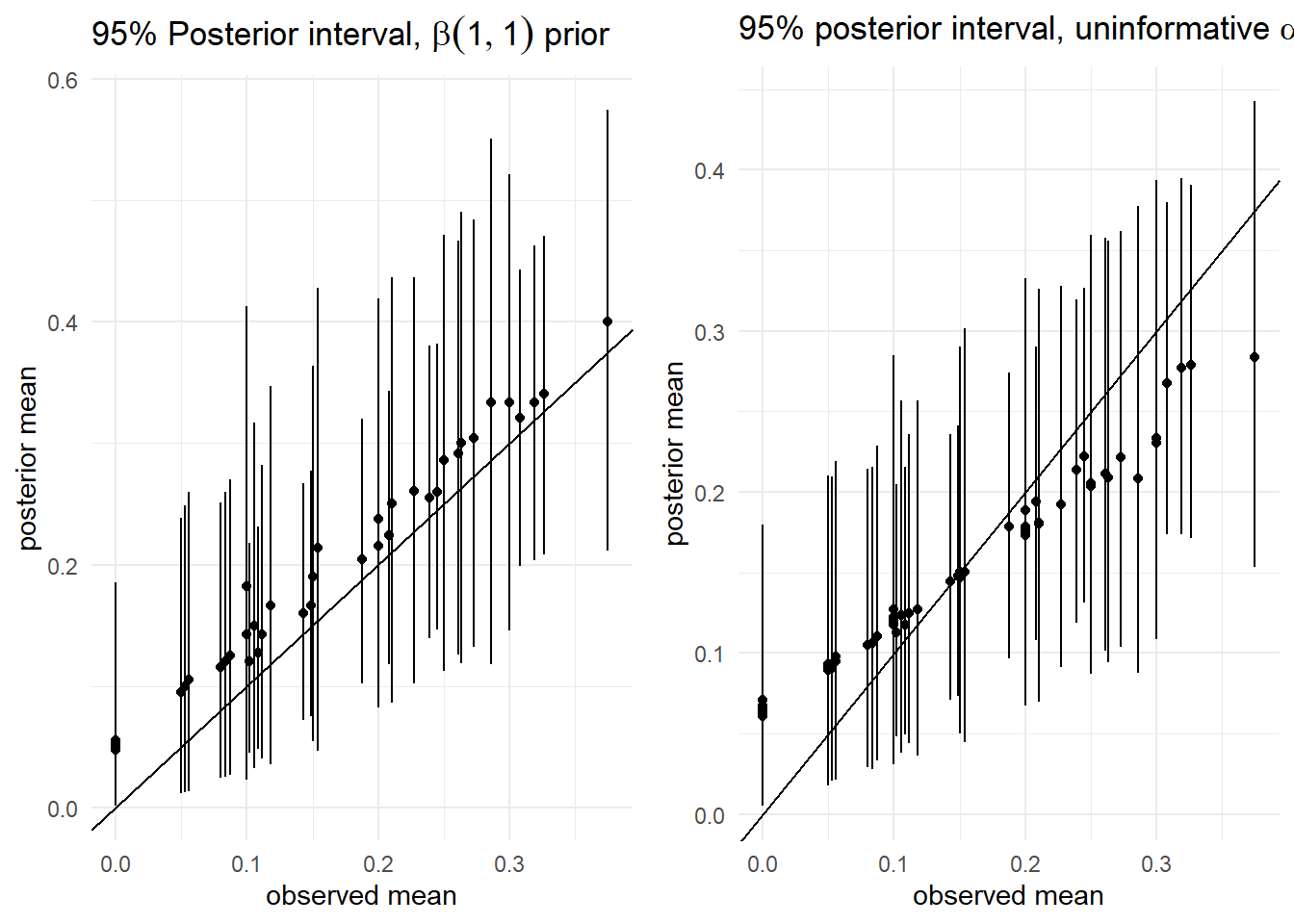
4) 1과 3 비교해보기
3. Hierarchical Normal
Conclusion
Prior의 Prior, HyperPrior를 활용하여 보다 설득력 있는 모델을 만들어보자!
Reference
[1] FCB
[2] ESC 2021-1 Spring 세션
혹시 궁금한 점이나 잘못된 내용이 있다면, 댓글로 알려주시면 적극 반영하도록 하겠습니다.